GPT Image 2: O Que Isso Muda Pra Quem Faz Vídeo

O GPT Image 2 apareceu três vezes no meu feed nas últimas 48 horas. Quando isso acontece, geralmente é uma de duas coisas: ou o produto é bom de verdade, ou alguém gastou muito em distribuição. Aprendi que não dá pra saber a diferença sem testar.
Antes de continuar: esse é um modelo de imagem, não de vídeo. Se você chegou aqui achando que o GPT Image 2 vai substituir seu fluxo de edição — não vai. Mas pra partes específicas do trabalho que vem antes do vídeo, as melhorias são reais o suficiente pra prestar atenção.
O Que É o GPT Image 2, de Verdade
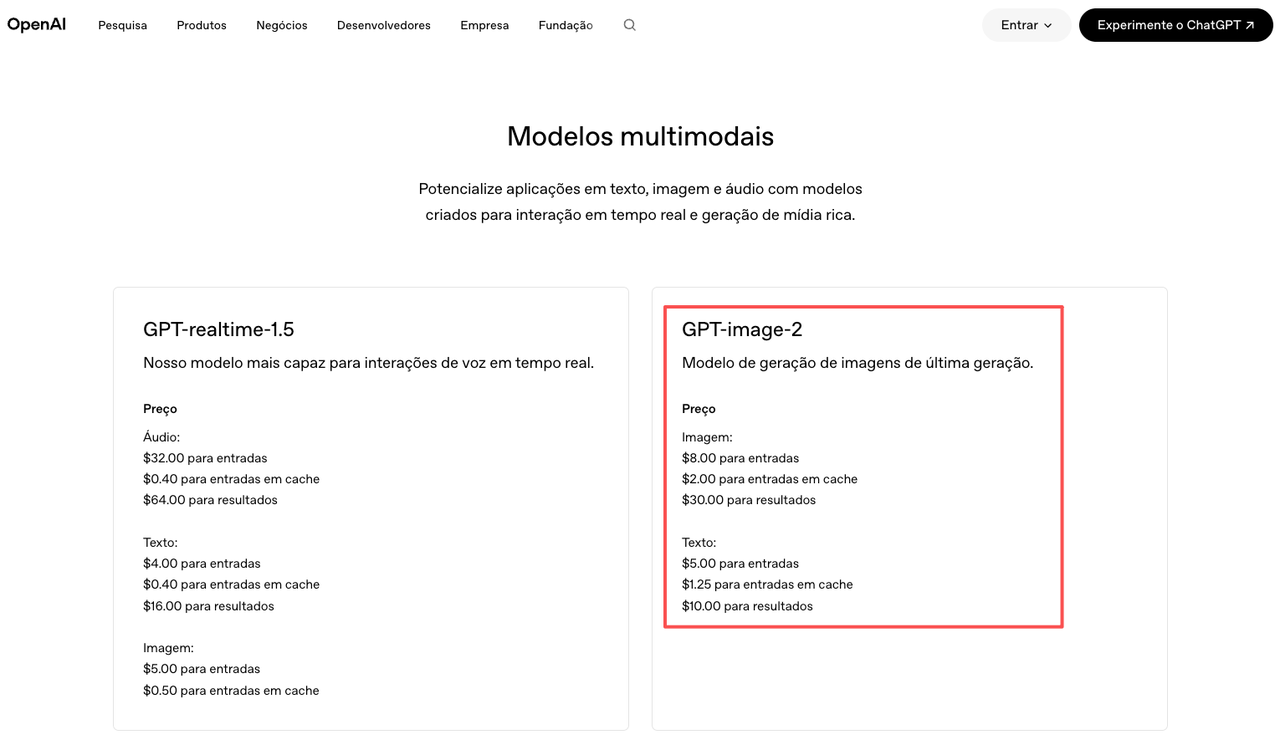
A OpenAI lançou o ChatGPT Images 2.0 em 21 de abril de 2026. O modelo — acessível via API como
gpt-image-2De acordo com a documentação oficial do modelo gpt-image-2, o snapshot do modelo é
gpt-image-2-2026-04-21
ChatGPT Images 2.0 vs. API gpt-image-2 — Mesmo Modelo, Dois Acessos
Mesmo modelo, duas camadas de acesso. No ChatGPT, aparece como ChatGPT Images 2.0. Na API, é
gpt-image-2Acesso por plano: básico pra todos, incluindo plano grátis. Geração múltipla e raciocínio avançado exigem Plus ($20/mês), Pro ou Business. Pra estimar custos antes de escalar, vale usar a calculadora disponível na página oficial de preços da API da OpenAI — os números que circulam no X e no Reddit agora não são confiáveis.
As 5 Funções Que Criadores de Vídeo Precisam Saber
Entrei com bastante ceticismo. Demo sempre parece melhor do que a realidade — isso é sempre verdade. Mas algumas coisas se sustentaram quando fui mais fundo.
Renderização de Texto com 99% de Precisão — Thumbnails e Títulos na Tela
Essa é a melhoria que mais aparece nos comentários, e é a que realmente segura.
Modelos anteriores da OpenAI eram inconsistentes com texto dentro de imagens. Palavras embaralhadas, letras erradas, espaçamento torto — qualquer um que já tentou gerar uma thumbnail com copy legível sabe como é. De acordo com o post de lançamento da OpenAI, o gpt-image-2 chega a mais de 99% de precisão na renderização de texto. Os testes independentes do LM Arena no período canário confirmaram: placas, overlays, strings com várias palavras, title cards estilizados — tudo substancialmente mais confiável.

Na prática pra quem faz vídeo: thumbnails com texto legível, title cards, frames com anotação de produto — tudo isso vira algo que dá pra gerar em vez de criar manualmente no Canva ou Figma.
Resolução Mais Alta — Frames em 2K Pra I2V
O modelo suporta até 2K de resolução, com 4K disponível em beta na API. Segundo a cobertura técnica do The New Stack sobre o lançamento, outputs acima de 2K são descritos como potencialmente inconsistentes em alguns casos.
Por que isso importa pra vídeo: se você usa imagens estáticas como frames de origem pra modelos de imagem-para-vídeo, resolução é uma limitação real. Frames de origem mais limpos e em alta resolução dão mais pra trabalhar pros modelos de vídeo downstream. Não é uma melhoria direta no seu output de vídeo — mas remove um gargalo antes dele.
Tipografia Multilíngue — Criadores Que Produzem em Outros Idiomas
O modelo agora lida com renderização de texto em japonês, coreano, chinês, hindi e bengali. Não é só "não vai embaralhar os caracteres" — é renderização localizada de verdade, com glifos e espaçamento corretos, segundo os detalhes de lançamento da OpenAI.

Se você produz conteúdo pra múltiplos mercados ou trabalha com clientes que precisam de assets localizados, isso muda o que é viável gerar. Antes, texto não-latino em imagens geradas por IA era praticamente inutilizável. Agora, segundo os primeiros testes, está funcionando.
Várias Imagens de um Único Prompt — Variantes de Thumb e Storyboards
Até oito imagens coerentes de um único prompt. Pra quem produz short-form, o uso óbvio é claro: gerar um conjunto de variantes de thumbnail ou frames de storyboard numa passada só, em vez de iterar uma imagem por vez.
Ainda estou no meio dos testes em volume. A estrutura funciona — só não rodei lotes suficientes pra saber onde a consistência quebra.

Marca d'Água e C2PA — O Que Isso Significa pra Conteúdo Comercial
Essa é a parte que mais importa se você produz conteúdo comercial.
Os outputs do GPT Image 2 embutem C2PA Content Credentials — um padrão de metadados com assinatura criptográfica que as principais plataformas já leem automaticamente. De acordo com a política de rotulagem de conteúdo IA do TikTok, a plataforma integrou a detecção C2PA em janeiro de 2025 e agora escaneia toda a mídia enviada. Se sua thumbnail ou frame gerado carregar metadados C2PA, TikTok, Instagram e YouTube podem aplicar automaticamente o rótulo "gerado por IA" independente das suas escolhas de divulgação.
Isso não é necessariamente um problema. Conteúdo de IA devidamente rotulado ainda é elegível pra monetização no TikTok sob as regras atuais. Mas se você usa outputs do GPT Image 2 em criativos de anúncios comerciais e quer controle sobre como a rotulagem aparece, entender como as C2PA Content Credentials interagem com a detecção das plataformas agora faz parte do trabalho.
O Que o GPT Image 2 NÃO Faz
A página de vendas fala em "nova era da geração de imagens." A realidade falou outra coisa quando fui ver o que ele de fato não faz.
Ainda é um modelo de imagem — sem geração de vídeo. Isso não dá pra deixar passar. O GPT Image 2 gera imagens estáticas. Não gera vídeo, não anima sequências, não produz movimento. Se você chegou aqui porque viu "GPT Image 2 pra criadores de vídeo" e assumiu que isso significava vídeo — o problema é de como está sendo coberto, não de uma capacidade do modelo.
Movimento, câmera e física continuam downstream. A OpenAI reconhece que o modelo ainda tem dificuldade com tarefas que exigem um modelo de mundo físico coerente — guias de origami, objetos em superfícies invertidas ou anguladas, detalhes repetitivos finos. Pra quem faz vídeo, a implicação é mais simples: qualquer movimento, câmera ou consistência temporal vem de um modelo de imagem-para-vídeo separado, depois. O GPT Image 2 te dá um frame de origem melhor. O que você faz com esse frame é trabalho de outra ferramenta.
Onde Isso Se Encaixa num Fluxo de Short-Form
Upstream — Geração de Frame de Origem
O ponto de inserção prático é antes da etapa de geração de vídeo:
Gerar candidatos de thumbnail com texto legível
Criar frames de referência de storyboard pra prompting de I2V
Produzir versões localizadas de title cards na tela
Montar conjuntos de variantes de anúncios pra teste A/B de ganchos
Downstream — Ainda Precisa de I2V, Legendas, Adaptação de Plataforma
O output do GPT Image 2 é uma imagem estática. O resto do fluxo de short-form — movimento, legendas, áudio, tamanho de plataforma, revisões — não muda. Você ainda precisa de um modelo I2V pra transformar frames em vídeo, uma camada de legendas, processamento de áudio e o ambiente de edição que já usa.
Três passos da ideia ao short-form publicável ainda não é três passos. O GPT Image 2 torna um desses passos mais rápido e confiável. Isso é útil. E também é tudo que é.
Sinal de Preço Inicial Pra Criadores
Não use os números por imagem que estão circulando no X e no Reddit agora. A precificação pública da OpenAI mapeia pra cobrança baseada em token. A página oficial de preços da API da OpenAI é a única fonte que vale a pena consultar — inclui uma calculadora de geração de imagem pra estimativas.
O que está confirmado: precificação varia por qualidade de output e resolução. Outputs em alta resolução custam mais. Usuários do plano grátis têm acesso básico. Recursos avançados exigem plano pago.
O Que Acompanhar nas Próximas Semanas
Gaps conhecidos: detalhe visual fino ou repetitivo ainda excede os limites de fidelidade em alguns casos. Rótulos e diagramas de peças podem precisar de revisão manual. Outputs acima de 2K estão em beta na API — resultados inconsistentes sinalizados pela própria OpenAI.
Política: metadados C2PA nos outputs significam que rotulagem automática de plataforma é possível mesmo sem autodivulgação. Se você usa outputs do GPT Image 2 pra criativos de anúncios comerciais, entenda como o C2PA interage com a detecção das plataformas antes de escalar. De acordo com o relatório de transparência do TikTok, a aplicação sobre conteúdo de IA não rotulado aumentou 340% na segunda metade de 2025. Isso é política existente aplicada a uma nova ferramenta.
Recepção das plataformas: ainda cedo. O modelo está ativo há menos de 24 horas no momento em que escrevo. Dados de desempenho do mundo real sobre se a renderização de texto segura em alto volume, se o C2PA dispara rotulagem automática na prática, e se a qualidade de output em 2K é consistente o suficiente pra uso em produção — nada disso existe ainda. Volta aqui em duas semanas.
FAQ Rápido
O GPT Image 2 é grátis? Acesso básico está disponível pra todos os usuários do ChatGPT, incluindo plano grátis. Recursos avançados — raciocínio nativo, geração múltipla de imagens — exigem Plus, Pro ou Business. Acesso via API é cobrado por token.
Posso usar os outputs comercialmente no TikTok/Reels? Conteúdo de IA devidamente rotulado pode ser monetizado no TikTok sob as regras atuais. A complicação é que os metadados C2PA nos outputs do GPT Image 2 podem disparar rotulagem automática pela plataforma independente das suas escolhas de divulgação. Considere isso pra conteúdo comercial.
Gera vídeo? Não. O GPT Image 2 gera imagens estáticas. Movimento exige um modelo de imagem-para-vídeo separado downstream.
A marca d'água é removível? As C2PA Content Credentials ficam nos metadados da imagem, não como marca d'água de pixel visível. Podem ser removidas salvando ou convertendo o arquivo — mas fazer isso pra evitar os requisitos de divulgação das plataformas coloca você em risco de política. As plataformas estão escaneando esses metadados.
Resumindo Pra Quem Faz Short-Form

O GPT Image 2 fecha uma lacuna específica: texto confiável em imagens, em resolução mais alta, em mais idiomas, com geração em lote. Pra produção de thumbnail, criação de frames de origem e geração de assets localizados, essas são melhorias reais que valem o teste.
Não muda seu fluxo de vídeo. Melhora uma etapa upstream dele.
Vale testar se você produz em volume e a precisão de texto em imagens tem sido um ponto de atrito consistente. Não é a transformação de fluxo de trabalho que a distribuição sugere.
Posso estar errada sobre essa parte — só rodei por um dia. Vou atualizar quando tiver mais dados.
Leituras Recomendadas
JoyAI Image Edit: O Que É e Por Que Criadores de Conteúdo Estão de Olho
Guia de Prompts pra Wan 2.7: resultados melhores de verdade
GPT Image 2: O Que os Criadores Precisam Saber Antes do Lançamento