Guia de Prompts no GPT Image 2 pra Criadores de Short-Form

Eu comecei errado. Meus primeiros dez prompts no GPT Image 2 foram basicamente prompts de pôster — cenas detalhadas, descrições de atmosfera, referências estéticas. Ficaram lindos.
Aí eu joguei tudo no meu pipeline de imagem-para-vídeo e metade quebrou no primeiro frame.
Oi, gente, sou a Mariana. Rostos foram derivando. O produto foi parar no canto errado. Um layout que parecia perfeito como imagem estática virou uma bagunça piscante assim que o movimento começou.
Esse é o gap que ninguém explica direito: gerar uma imagem pra short-form é uma tarefa completamente diferente de gerar uma imagem que simplesmente parece boa.
As decisões visuais que você toma na fase do prompt definem se o seu fluxo de criação de conteúdo vai funcionar ou vai travar quietinho — e você só descobre quando tá olhando pra um export inutilizável duas horas depois.
Esse é o SOP de prompt que eu queria ter tido. Não é uma enciclopédia de prompts. É um framework de decisão pra criadores que produzem em volume e precisam que as imagens façam trabalho de verdade.
O Que Um Prompt Pronto Pra Short-Form Precisa Ter
Composição, Texto e Preparação pro Movimento
O que separa um frame-fonte de uma imagem bonita é que o frame-fonte precisa sobreviver ao movimento. Isso significa que três coisas precisam ser decididas no nível do prompt — não na edição.
Isolamento do sujeito. Se o seu sujeito se mistura com o fundo por bordas suaves ou oclusão ambiente que combina com o frame inteiro, os modelos de imagem-para-vídeo vão animar as coisas erradas. Peça separação visual. "Subject on plain surface with clearly defined shadow" bate "dramatic atmospheric composition" toda vez.

Posicionamento do texto. O GPT Image 2 lida bem com texto dentro da imagem quando você é explícito. O guia oficial de geração de imagem da OpenAI recomenda colocar o texto exato entre aspas e especificar o posicionamento com precisão: "Bold sans-serif headline reading 'LAST DAY' in top-left quadrant, no overlap with center subject." Se o texto fica perto demais do centro ou sangra nas bordas, vai competir com as legendas sobrepostas ou ficar escondido pelo chrome da plataforma.
Zonas estáticas. Modelos de animação interpretam seu frame-fonte espacialmente. Elementos perto das bordas costumam ser puxados ou distorcidos primeiro. Mantenha qualquer coisa que precise ficar legível — texto de marca, rótulos de produto, rostos — dentro dos 80% centrais do frame.
O Que Decidir Antes de Escrever o Prompt
A maioria das falhas de prompt acontece porque essas decisões foram deixadas pro modelo resolver:
Proporção e formato de saída. 9:16 pro TikTok e Reels, 1:1 pro feed. Diga explicitamente. O GPT Image 2 suporta os tamanhos e proporções oficiais documentados pela OpenAI de forma flexível, mas não vai adivinhar sua plataforma.
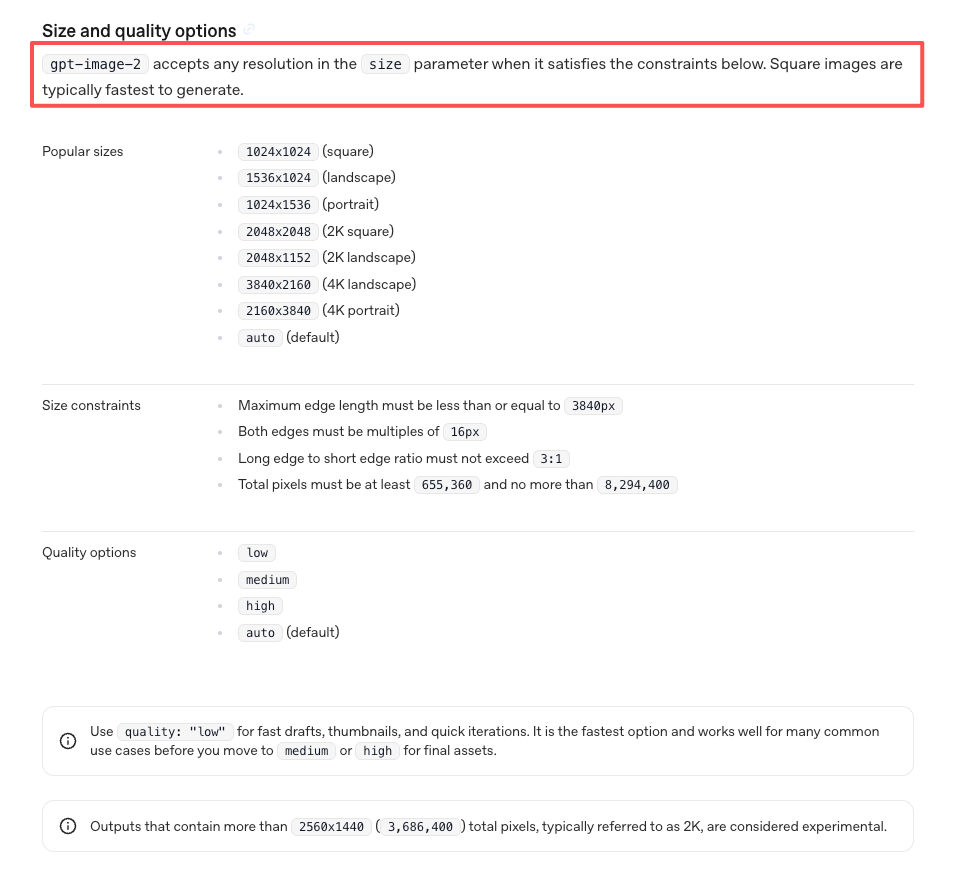
Objetivo da saída. Isso é uma thumbnail (estática, alto contraste, legível em tamanho pequeno), um frame-fonte (vai animar), ou um hook de anúncio UGC (precisa passar no teste de scroll no primeiro frame)? A lógica do prompt muda pra cada um.
O que precisa ficar fixo vs. o que pode variar. Isso importa mais quando você tá gerando várias versões. Decida antes: fixo = pose do sujeito, direção da iluminação, texto. Variável = cor de fundo, textura, elementos secundários.
Framework de Prompt Que Dá pra Reusar
Sujeito, Enquadramento, Texto, Identidade de Marca, Objetivo
Essa é a estrutura que eu passo todo prompt antes de gerar qualquer coisa:
[Descrição do sujeito] + [Enquadramento e composição] + [Iluminação] + [Texto se necessário, entre aspas] + [Estilo/mood] + [Restrição de saída]
Um exemplo real pra thumbnail de produto:
"Skincare serum bottle, center frame, clean white marble surface, dramatic side lighting casting defined shadow to the right, text reading 'SOLD OUT TWICE' in bold sans-serif at top-left, minimal lifestyle aesthetic, 9:16 vertical, no text clutter below the product"

Esse prompt roda de forma consistente. A estrutura dá ao modelo informação suficiente pra não precisar adivinhar, mas não sobrecarrega com prioridades competindo entre si.
Instruções Negativas e Linguagem de Restrição
Essa é a parte que a galera pula e depois fica se perguntando por que os outputs são inconsistentes.
Restrições negativas funcionam diferente no GPT Image 2 em comparação com modelos de difusão. Você não escreve "negative prompts" — você escreve restrições de instrução diretamente no prompt principal. O modelo responde a linguagem direta: "no text other than the specified headline", "no props outside the product", "no grain or texture on subject's skin."
A documentação da comunidade no fórum de desenvolvedores da OpenAI tem um padrão útil: declare o que NÃO pode mudar antes de descrever o que deve acontecer. Essa ordem importa — o modelo usa as restrições como âncoras quando resolve ambiguidades.
Receitas de Prompt por Caso de Uso
Prompts pra Thumbnail e Imagem de Capa
Thumbnails têm um trabalho só: parar o scroll e comunicar algo em 200px. As decisões de prompt que importam aqui são alto contraste, texto mínimo e um sinal emocional ou de resultado que lê instantaneamente.
Template:
"[Pessoa/produto] com [expressão emocional forte ou visual-chave], [cor de fundo de alto contraste], texto em negrito lendo '[TEXTO EXATO]' no terço superior, enquadrado em [close/plano médio], limpo e sem poluição visual, 9:16"
Nota de iteração: mude uma variável por vez. Cor de fundo → posição do texto → expressão do sujeito. Gerar 10 variantes aleatórias ao mesmo tempo torna impossível saber o que tá funcionando.
Prompts pra Frame-Fonte de Imagem-para-Vídeo
Aqui foi onde eu desperdicei mais tempo no início. O erro: gerar imagens bonitas e descobrir que quebram na animação porque a composição não dá ao modelo de movimento uma hierarquia espacial clara pra trabalhar.
Entender como modelos de vídeo interpretam composição e profundidade no frame de entrada mudou completamente como eu estruturo meus prompts.
O que funciona pra frames-fonte:
Um sujeito dominante, claramente separado do fundo
Ângulo de câmera que implica direção de movimento (ângulo levemente baixo com sujeito um pouco fora do centro implica push-in em direção ao sujeito)
Sem texto perto das bordas ou nos limites do frame
Profundidade definida — sujeito em primeiro plano, distância média e fundo, distintos entre si
O princípio é que texto descreve movimento, imagens definem composição. Quando seu frame-fonte tem hierarquia composicional clara, o prompt de movimento tem menos pra resolver e produz clipes mais previsíveis.
Template:
"[Sujeito] posicionado [centro-esquerda/direita], [fundo limpo com profundidade visível], iluminação de [direção] criando sombra definida, sem artefatos de movimento, composição limpa pra input de animação, [proporção]"
Prompts de Hook pra Anúncio UGC
O frame de hook é a primeira coisa que um comprador em potencial vê antes de decidir assistir ou rolar. Segundo as boas práticas oficiais do TikTok for Business pra hooks de vídeo, 90% do impacto de recall de um anúncio é capturado nos primeiros seis segundos — o que significa que o frame de abertura carrega um peso desproporcional na decisão de continuar assistindo.
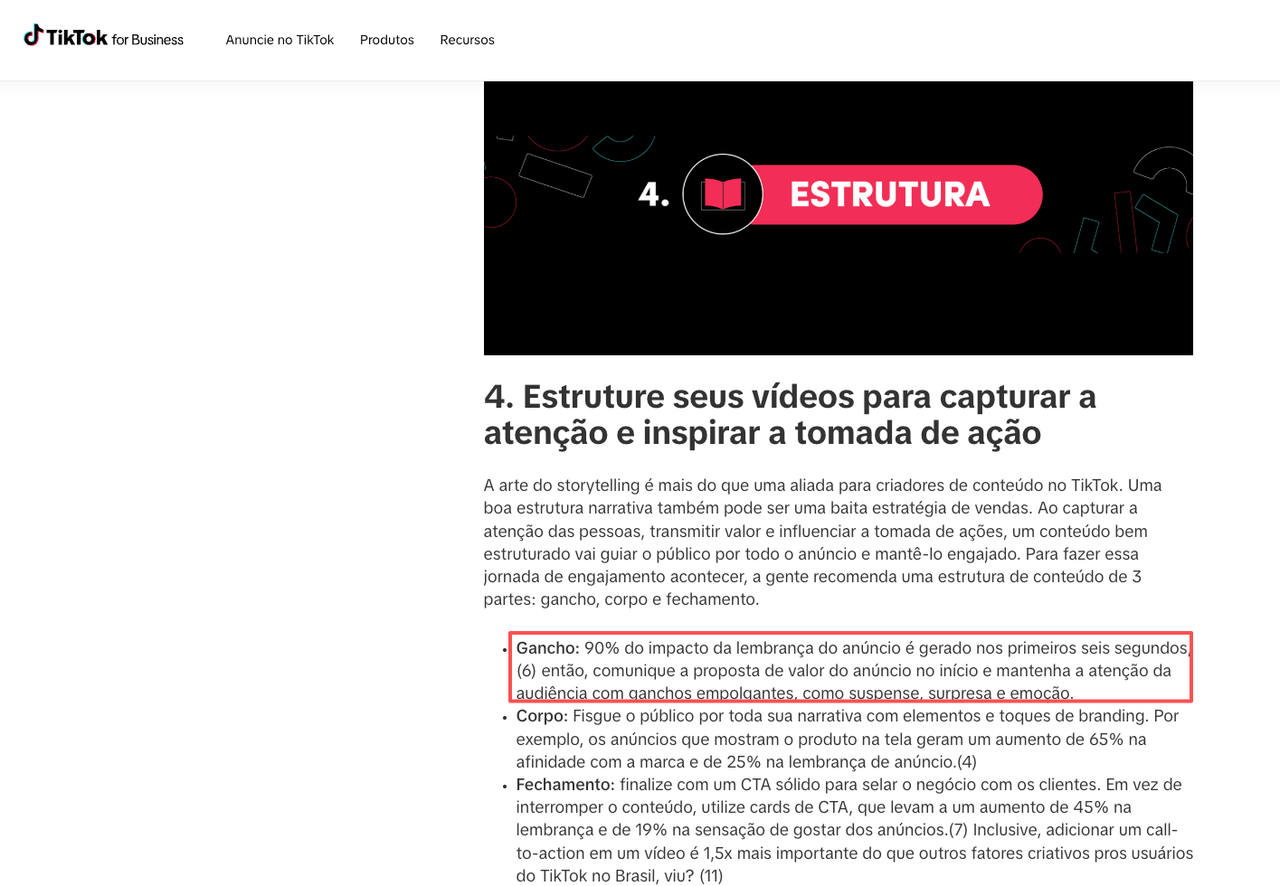
Duas coisas importam: precisa parecer real o suficiente pra quebrar o reconhecimento de padrão, e precisa comunicar o benefício do produto antes de qualquer texto ser lido.
O que quebra frames de hook UGC no nível do prompt:
Polido demais — lê como anúncio imediatamente
Sem contexto ambiental — produto flutuando no branco parece catálogo, não UGC
Texto que explica em vez de provocar
Template pra hooks estilo UGC:
"Fotografia estilo handheld de [produto em uso], iluminação natural interna com leve imperfeição, contexto ambiental visível ([bancada da cozinha / mesa / prateleira do banheiro]), composição espontânea levemente fora do centro, 9:16, sem clima de estúdio, textura autêntica"
A instrução "textura autêntica" empurra o modelo pra longe do output super-liso que lê como gerado.
Prompts pra Visual de Produto
Fotos de produto pra short-form têm uma restrição diferente dos stills de e-commerce: precisam funcionar em tamanho pequeno e durante o movimento. Um produto flutuando em fundo branco seamless parece ótimo num lookbook. Parece antisséptico num anúncio de short-form.
O fix prático: dê ao produto uma superfície e uma cena, não só um fundo.
"[Nome/tipo do produto] em [material da superfície], de [ângulo], [descrição da iluminação], estilizado com [1–2 props contextuais no máximo], sem logos além do próprio produto, 1:1 ou 9:16, paleta de cores: [2 cores]"
Falhas Comuns de Prompt
Texto Demais em Um Frame
O GPT Image 2 lida com texto melhor do que qualquer modelo anterior que eu testei. Mas "consegue lidar" não é "vai fazer por padrão."
Sobrecarregar um único frame com título + subtexto + badge + aviso cria um problema de layout que o modelo resolve deixando tudo menor. Resultado: texto que parece legível no preview da geração fica ilegível quando o vídeo é assistido no celular.
Regra que eu aplico: um elemento de texto por passagem de geração. Se você precisa de título e badge de preço, gere a imagem base primeiro, depois edite o texto secundário.
Layouts Que Quebram na Animação
Imagens composicionalmente complexas — elementos sobrepostos, vinhetas pesadas nas bordas, múltiplos planos de profundidade no mesmo nível — produzem movimento mais caótico quando animadas.
O modelo animando seu frame-fonte tenta inferir profundidade espacial. Quando o frame-fonte tem pistas de profundidade ambíguas, você recebe artefatos de movimento: fundos que "respiram" em velocidades diferentes do sujeito, bordas que distorcem, texto que vibra levemente. Isso acontece porque, como mostra a pesquisa do Gen-3 Alpha da Runway sobre coerência temporal entre frames, modelos de vídeo usam captions temporalmente densas pra inferir a estrutura espacial da cena — e quando a composição é ambígua, essa inferência falha.
Fix no nível do prompt: separação de profundidade explícita. "Clear foreground, middle ground, and background, distinct depth planes, no overlapping elements."
Inconsistência de Personagem e Produto
Você gera um personagem ou produto em três ângulos e a iluminação muda entre eles, o rótulo do produto muda, ou o rosto deriva levemente. Isso é o maior bloqueador pra conteúdo com storyboard.
O fix é a técnica de "âncora de identidade": declare os invariantes uma vez no topo do prompt, depois deixe cada painel descrever apenas o que muda. Não redescreva o personagem inteiro pra cada ângulo — declare as âncoras (cor do cabelo, roupa, texto específico do rótulo) uma vez, depois adicione só o delta.
Como Revisar em Vez de Recomeçar do Zero
Prompts de Iteração Que Preservam o Que Tá Funcionando
Recomeçar do zero é o hábito mais caro num fluxo de criação com IA. Quando uma geração tá 80% certa, use o endpoint de edição em vez de re-gerar.
A estrutura que funciona:
"Preserve: [liste os elementos que estão corretos]. Change: [exatamente o que precisa mudar]. Constraints: [o que não pode derivar — sem mudança de logo, sem mudança de fundo, mesma iluminação]."
Essa estrutura de três partes — preserve / change / constraints — impede o modelo de tratar tudo como aberto pra mudança. Sem ela, "deixa o texto mais bold" pode produzir uma versão onde o texto ficou mais bold mas o fundo mudou e a posição do produto alterou.
Quando Passar os Fixes pro Editor
O prompt não é a ferramenta certa pra todo fix. Para de prompar e vai pro editor quando:
O problema é gradação de cor ou saturação que precisa de controle preciso
Você precisa reposicionar texto em pixels exatos
O fix é um ajuste de crop ou escala
Você tá na 5ª iteração e o elemento que precisa mudar continua afetando outros elementos
Prompting é pra decisões de composição, tom e conteúdo. Correções em nível de pixel são trabalho de editor. Errar essa divisão é um dos sumidouros de tempo mais comuns que já documentei — re-prompar algo que levaria 45 segundos num editor.
FAQ
Quão detalhado deve ser o prompt? Seja específico, mas não exaustivo. Inclua só os detalhes que realmente afetam o output. Deixa o resto ser inferido pelo modelo. Regra prática: se remover uma frase não muda o resultado, deleta.
O GPT Image 2 lida bem com texto de marca? Sim, significativamente melhor do que modelos anteriores. Coloque o texto exato entre aspas, especifique estilo de fonte e posicionamento, e adicione "verbatim — no extra characters" pra strings críticas como precificação, nomes de produto ou CTAs. Onde ainda tem dificuldade: strings muito longas (mais de 8–10 palavras), texto pequeno abaixo de aproximadamente 12pt na resolução padrão, e texto em superfícies curvas.
Qual estilo de prompt funciona melhor pra imagem-para-vídeo? Comece com composição e clareza espacial. Descreva separação de profundidade explicitamente. Evite elementos sobrepostos complexos. O erro mais comum: escrever prompts cinemáticos que produzem stills lindos com profundidade ambígua. Lindo pra pôster. Problemático como frame-fonte.
Quando criadores devem parar de prompar e começar a editar? Quando você tentou corrigir o mesmo problema três vezes e cada tentativa causa outros elementos mudarem ou quebrarem. Esse é o sinal. Separa as responsabilidades: prompts cuidam de composição e estrutura; editores cuidam de correções em nível de pixel.
Essa diferença entre "imagem bonita" e "imagem pronta pra short-form" é quase totalmente uma decisão de prompt. Composição que sobrevive à animação, texto que lê no tamanho mobile, separação do sujeito que dá aos modelos de movimento algo claro pra trabalhar — essas não são ajustes de pós-produção. São decisões de prompt.
Meu fluxo real parece assim: decido o objetivo de saída antes de abrir um prompt, passo a estrutura preserve/change/constraints em toda edição, e movo os fixes pro editor assim que iterei duas vezes no mesmo elemento.
O caminho mais rápido pra output consistente não é prompts melhores isoladamente — é saber quais decisões pertencem ao prompt e quais não pertencem.
Você usa GPT Image 2 no seu setup? Me conta nos comentários qual tipo de conteúdo você tá gerando — quero comparar com o que vi nos meus testes.
Leituras Recomendadas
Como transformar imagens do GPT Image 2 em vídeos curtos