GPT Image 2 pra vídeo: como transformar imagens de IA em clipes curtos

Mesma lógica de sempre: uma ferramenta pra gerar a imagem, três pra animar. Cronometrei tudo usando uma foto de produto real e um prazo real.
Depois de testar os outputs do GPT Image 2 em vários modelos de imagem-para-vídeo, uma coisa ficou clara: o gargalo não é a animação — é a imagem de entrada.
Nota rápida: o que as pessoas chamavam de "GPT-4 image" agora é o GPT Image 2 — lançamento oficial ChatGPT Images 2.0 (API:
gpt-image-2O insight principal é simples: se a sua imagem tem composição ruim, profundidade fraca ou fundo bagunçado, nem o melhor modelo de vídeo vai salvar. Mas se você acertar a imagem, a animação fica muito mais previsível.
Aqui está o que realmente funciona em 2026 — e onde quebra.
Por que a qualidade da imagem define o output do I2V
O que torna uma imagem gerada "pronta pra animar"
Errei feio na primeira vez. Gerei um flatlay de produto com fundo cheio de textura, joguei no Kling 3.0 esperando movimento suave. O que saiu foi shimmer no fundo, artefatos nas bordas do produto e três segundos de footage inutilizável. A imagem estava visualmente limpa. O problema era que ela não dava nada pro modelo ancorar o movimento.
Uma imagem pronta pra animar tem três coisas que o modelo consegue trabalhar:
Um único sujeito sem ambiguidade. Modelos I2V leem profundidade e paralaxe pelas bordas dos objetos. Vários sujeitos sobrepostos confundem os vetores de movimento — você acaba com emendas borradas onde o modelo não sabe o que deve mover e o que deve ficar parado. Um sujeito, claramente separado.
Pistas de profundidade direcional. Imagens planas e iluminadas de forma uniforme animam mal. O modelo precisa de um primeiro plano, um plano médio, um fundo — mesmo que implícito. Um gradiente sutil, uma sombra suave, um plano de fundo desfocado. Esses elementos dão ao modelo algo pra empurrar quando simula movimento de câmera.
Espaço negativo limpo. Não vazio — negativo. Precisa ter espaço ao redor do sujeito. É isso que permite que modelos I2V adicionem movimento natural, como um zoom lento ou uma flutuação suave, sem bater imediatamente numa parede composicional.
Specs de imagem que reduzem falhas de movimento
Acompanhei a taxa de retrabalho em 40 gerações ao longo de duas semanas. Aqui está o que correlacionou com taxas de falha menores:
Resolução: 1024×1024 no mínimo. O GPT Image 2 agora suporta até resolução 2K — gere na tier de qualidade mais alta que você conseguir, porque artefatos I2V se amplificam em resoluções menores.
Proporção: Gere na proporção que vai animar. Se você está fazendo um clipe 9:16 pro TikTok, gere a imagem em 9:16. Cortar depois muda a composição de formas que quebram o frame.
Iluminação: Fonte única ou difusa. Iluminação cruzada dura cria ruído nas bordas quando o movimento começa. Iluminação frontal suave ou a 45 graus é a mais estável.
Fundo: Sólido, gradiente simples ou intencionalmente desfocado. Um fundo com muito detalhe de textura vai ter shimmer no primeiro frame de movimento — toda vez, sem exceção.
Quando segui essas specs, minha taxa de retrabalho nos outputs I2V caiu de cerca de 65% para aproximadamente 20%. Esse é o número que importa se você está rodando isso em volume.
3 casos de uso onde o GPT Image 2 alimenta vídeo
Packshot de produto → clipe de lifestyle em movimento
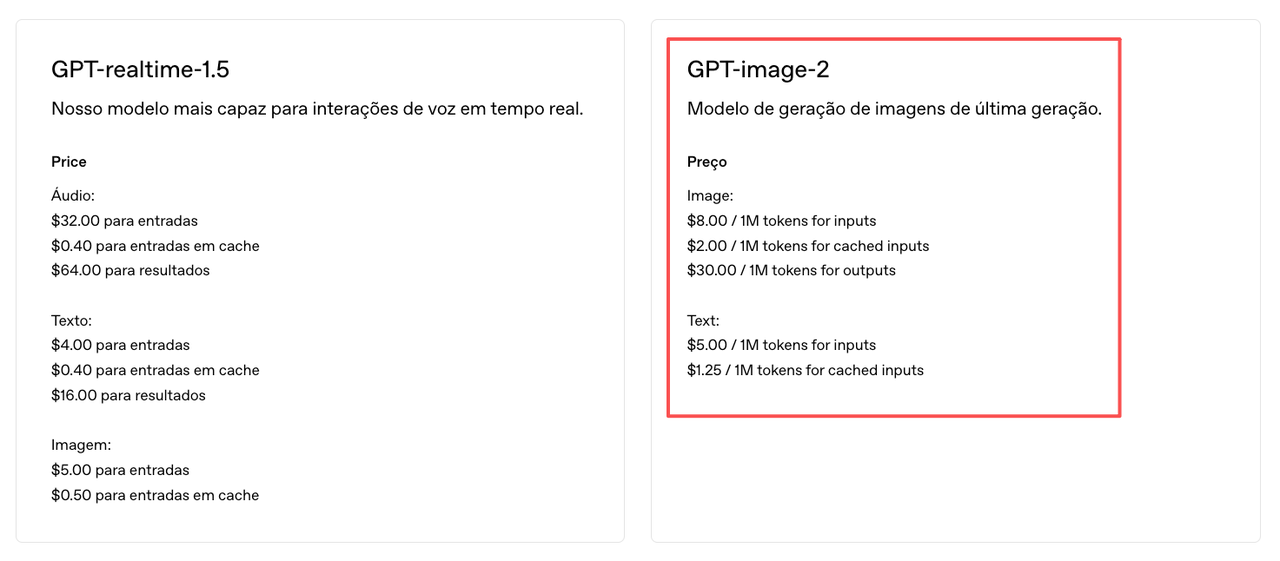
Alto ROI pra e-commerce. Gere uma foto limpa do produto, depois anime numa rotação ou flutuação de 4–6s. Isso substitui um shoot de motion de produto pra maioria dos casos de anúncio em short-form. O custo de geração via API da OpenAI — tabela de preços gpt-image-2 é $8,00 por 1M de tokens de input e $30,00 por 1M de tokens de output — o custo por imagem fica em torno de $0,02–$0,20 dependendo da resolução e tier de qualidade. Um clipe de lifestyle que antes precisava de meio dia em estúdio agora custa menos de um dólar em custos de geração.
Vale mencionar: de acordo com os termos de serviço da OpenAI, você é dono do output e pode usar comercialmente, incluindo em anúncios pagos. Essa pergunta aparece o tempo todo — a resposta é sim, com o mesmo aviso que se aplica a todo output de IA: você é responsável por garantir que nenhum direito de terceiros esteja incorporado sem querer.
Imagem de fundo de cena → curta cinematográfico
Crie uma placa de ambiente, depois anime com um pan lento ou push-in. Adicione produto ou footage talking-head em pós. É uma alternativa mais barata e escalável do que licenciar B-roll.
Gráfico de redes sociais → card de story animado
Surpreendentemente eficaz. O GPT Image 2 lida bem com texto e layouts, e designs simples animam com mais consistência. Um efeito básico de zoom ou motion pode transformar gráficos estáticos em conteúdo de story utilizável com mínimo de retrabalho.

Como fazer prompt no GPT Image 2 pra outputs prontos pra vídeo
Regras de composição — sujeito único, fundo limpo
A estrutura de prompt que consistentemente produziu outputs prontos pra animar nos meus testes seguiu esse padrão:
[Sujeito único] + [descritor de iluminação específico] + [descritor de fundo] + [indicador de profundidade] + [o que excluir]Exemplo: "uma única garrafa de vidro de azeite de oliva, luz lateral suave vindo da esquerda, fundo gradiente branco-cinza simples, sombra sutil na superfície abaixo, sem texto, sem props, sem outros objetos"
A parte de exclusão importa. O GPT Image 2 tende a adicionar elementos decorativos extras se você for vago. Chamá-los explicitamente no prompt economiza tempo.
Um upgrade útil: o GPT Image 2 consegue interpretar intenção. Se você diz que a imagem vai ser animada (ex: "para um clipe de zoom lento no TikTok"), ele frequentemente produz composições mais limpas e amigáveis pra animação.
Pistas de iluminação e profundidade que ajudam modelos I2V a ler a imagem corretamente
Iluminação afeta o movimento, não só a estética:
Iluminação frontal suave → movimento estável e previsível
Iluminação lateral dramática → mais dinâmico, mas risco maior de artefatos
Pra profundidade, adicione explicitamente:
"shallow depth of field"
"leve desfoque no fundo"
Isso melhora a separação sujeito-fundo, ajudando modelos I2V a gerar paralaxe mais limpa e movimento temporal consistente.
Pesquisas sobre geração de imagem-para-vídeo guiada por profundidade confirmam que sinais de profundidade monocular — sombras projetadas, separação de bordas, distância de objetos — são exatamente as pistas que modelos de difusão I2V usam pra construir vetores de movimento e manter consistência temporal. Fazer prompt pra eles não é um workaround. É usar o mecanismo subjacente corretamente.
O pipeline de edição pós-geração
Animando com modelos I2V (quais inputs usar)
Meu stack atual:
Kling 3.0: Melhor pra animação de produto e volume. Aproximadamente $0,11–$0,17 por segundo (baseado em créditos; alinhado com tiers oficiais de API e assinatura). Consistência de sujeito superior em batches.
Runway Gen-4.5: Quando fidelidade visual e controle de trajetória de câmera importam mais do que custo. Controles de motion brush e pull-back / push-in / lateral drift precisos fazem dele o ideal pra conteúdo hero. Atualmente lidera o benchmark de Text-to-Video da Artificial Analysis.
Veo 3.1: Pra composição de talking-head e sincronização nativa de áudio/lip-sync. O suporte a múltiplas imagens de referência como "ingredientes" agora facilita a consistência de personagem e estilo.

A recomendação prática de uma comparação independente de modelos de vídeo IA em 2026: não se comprometa com um modelo só. Misture por tipo de conteúdo. Kling pra volume, Runway pra controle, Veo quando o áudio importa.
Adicionando legendas e sobreposições de texto pra visualização sem som
Mais de 85% dos vídeos short-form são assistidos sem som no primeiro scroll. O clipe animado é só parte do asset. Legendas e sobreposições de texto entram em pós — isso não é algo que modelos I2V fazem de forma confiável.
Meu fluxo atual: o clipe animado sai da ferramenta I2V, vai pra uma ferramenta de legendas (geradas automaticamente, depois corrigidas pontualmente), e as sobreposições de texto são adicionadas num editor de vídeo com um template. O passo de pós inteiro adiciona cerca de 8 minutos por clipe quando o template está pré-construído.
Um passo manual a menos. Todo dia. Isso vai acumulando — e o template de legendas é onde a maior parte desse tempo é recuperado.
Exportando pras specs do TikTok, Reels e Shorts
As três specs com que você vai trabalhar:
Plataforma | Proporção | Resolução | Duração máxima |
TikTok | 9:16 | 1080×1920 | 10 min (anúncios: 60s) |
Instagram Reels | 9:16 | 1080×1920 | 90s |
YouTube Shorts | 9:16 | 1080×1920 | 60s |
As três principais plataformas usam 9:16 a 1080×1920 idênticos. Gere e anime nessa proporção. Anúncios horizontais precisam de uma passagem separada — cortar quase sempre quebra a composição.
Limitações desse pipeline
Consistência de personagem em múltiplos shots

Essa é a restrição real. Se você precisa da mesma pessoa ou personagem em vários clipes, o pipeline GPT Image 2 → I2V ainda tem dificuldades.
O GPT Image 2 consegue gerar até oito imagens consistentes em um único batch, o que ajuda. Mas em runs I2V separadas, pequenas diferenças aparecem — formato do rosto, cor dos olhos, cabelo. Pra visuais só de produto, tá ótimo. Pra pessoas ou avatares, é uma limitação.
Workarounds existem, mas nenhum é ideal: reutilizar a mesma imagem seed (menos variedade), ou corrigir consistência em pós. Ferramentas como o Kling 3.0 tentam resolver isso, mas workflows cross-tool ainda introduzem drift.
O que o GPT Image 2 não consegue controlar — direção de movimento, timing
Geração de imagem não tem consciência de animação. Você não consegue projetar uma imagem "para" um movimento de câmera — o movimento vem depois.
Então o workflow é sempre unidirecional: gere primeiro, anime depois. Se a composição não encaixar no movimento, você tem que refazer a imagem — não ajustar a animação.
A solução prática: aprenda quais composições de imagem funcionam com quais movimentos, e construa uma pequena biblioteca de pares imagem-movimento confiáveis. Isso é mais útil do que qualquer truque de prompt isolado.
FAQ
Os outputs do GPT Image 2 podem ser usados em vídeos comerciais?
Sim. Pelos termos de serviço atuais da OpenAI, você é dono do output e pode usar comercialmente, incluindo em publicidade paga. O aviso: o US Copyright Office indicou que obras puramente geradas por IA sem input humano significativo podem não receber proteção de copyright. Pra assets críticos de marca, adicione especificidade suficiente direcionada por humanos no prompt e em pós-edição pra estabelecer autoria criativa significativa.
Como acesso o GPT Image 2?
Via ChatGPT — disponível pra todos os usuários de ChatGPT e Codex a partir de 21 de abril de 2026, com recursos de pensamento avançado restritos aos planos Plus, Pro e Business. Também disponível via API da OpenAI — documentação gpt-image-2 como
gpt-image-2Quais modelos I2V funcionam melhor com imagens geradas por IA?
Kling 3.0 (volume + produto), Runway Gen-4.5 (controle criativo), Veo 3.1 (sincronização de áudio). Todos aceitam inputs de imagem estática diretamente.
Consigo manter consistência de personagem entre shots?
A geração de múltiplas imagens do GPT Image 2 (até 8 por prompt) melhora a consistência dentro de um único batch. Consistência cross-session e cross-tool — especialmente após o passo I2V — ainda drifta. Pra conteúdo só de produto, essa limitação não se aplica. Pra campanhas com personagem, inclua uma passagem de QC manual.
Isso é mais barato do que comprar stock footage?
Pra assets de produto únicos e específicos de marca: sim, significativamente. Pra B-roll genérico, stock ainda pode competir quando você leva em conta o tempo de geração. O pipeline brilha com 5+ assets por semana.
Esse pipeline vale a pena construir se você está produzindo 5+ assets de vídeo short-form por semana pra conteúdo de produto ou e-commerce. Abaixo desse volume, o tempo de setup não justifica o ganho de eficiência. Acima disso, o loop de geração de imagem → animação → legenda → exportação se acumula em horas reais economizadas por semana.
Se você está rodando uma campanha única ou testando o formato pela primeira vez: comece com um produto, um prompt de imagem, um modelo I2V. Faça esse loop funcionar antes de otimizar o stack.
Leituras Recomendadas
Como transformar imagens do GPT Image 2 em vídeos curtos
GPT Image 2: O Que Isso Muda Pra Quem Faz Vídeo
Geradores de Avatar com IA e Templates de Cena para E-Commerce