GPT Image 2: What Creators Need to Know Before It Launches

I went in pretty skeptical when I first saw the thread. Three codenames that sound like a hardware store receipt. No company name attached. Outputs that people were sharing like they'd witnessed something unusual.
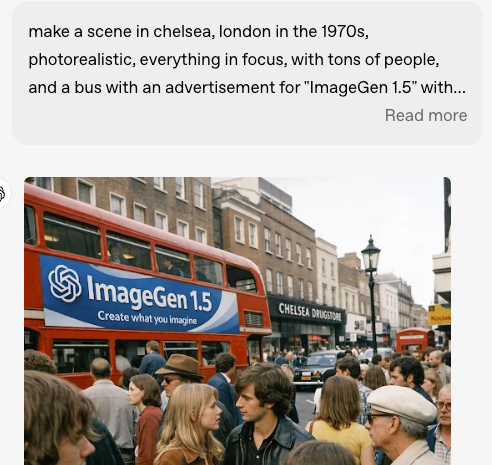
But then I looked at the images. Text that is actually rendered. A yellow tint that wasn't there. Scenes that looked like they knew where they were set.
This was April 4, 2026. Three anonymous models appeared on LM Arena — the public benchmark platform where users compare AI models in blind tests — under the names maskingtape-alpha, gaffertape-alpha, and packingtape-alpha. Within hours, the AI community had a working theory: OpenAI's next image generation model. Within more hours, all three were pulled.
I've been running gpt-image-1 in short-form video pipelines since it launched in March 2025. Whether what leaked is called "GPT Image 2" or gets renamed before shipping — none of that changes the practical question: what does this mean for creators building visual assets for video content?
That's what this piece covers. Not hype. A clear look at what's reportedly different, where it matters for a content pipeline, and what to actually wait on before changing anything.

What GPT Image 2 Is — And How We Know It Exists
The Arena leak: three codenames, one model
On or around April 4, 2026, three anonymous image models codenamed “packingtape-alpha,” “maskingtape-alpha,” and “gaffertape-alpha” appeared on LM Arena in blind tests. Community testers quickly noted unusually strong text rendering and world knowledge. All three models were pulled within hours — the same pattern OpenAI followed when testing earlier image models.
That pattern is worth noting. OpenAI has used anonymous Arena testing before, and the timing followed the shutdown of Sora on March 24, 2026, which was officially attributed to compute reallocation.

Confirmed vs. reported details
Confirmed: Three codenamed models appeared on LM Arena in early April 2026 and were removed shortly after community attention. OpenAI has not issued any official statement.
Reported by testers: Significantly improved text rendering, elimination of the yellow color cast seen in GPT Image 1.5, stronger multi-object scenes, and better overall prompt adherence.
Still unconfirmed: Exact release name, timeline, pricing, or final architecture.
I’m treating this as a credible signal that a meaningful upgrade is coming — not as final product specs.
4 Upgrades That Matter for Creators
Text-in-image accuracy — finally usable for social graphics
Previous models struggled with non-Latin scripts and complex overlays. Early testers reported near-perfect text rendering across English and multilingual prompts, making the output immediately usable for on-screen copy, CTAs, product pricing, and caption templates.
For short-form video creators, this removes the biggest pain point: generating 10–15 images just to get one with readable, correctly spelled text.
Photorealism improvements and yellow tint fix
Testers consistently noted the complete removal of the yellow/sepiatone bias that plagued GPT Image 1.5 outputs. Images appeared more photograph-like, with better color fidelity and lighting.
This matters for e-commerce and ad creative: higher-fidelity source images hold up better when fed into image-to-video (I2V) tools.

Multi-object compositional control
Complex scenes — product arrangements, lifestyle shots, spatial relationships — showed stronger coherence. Testers highlighted accurate world knowledge in outputs involving real locations, interfaces, and contextual details.
Faster prompt adherence (reported)
Generation speed improvements were noted in blind testing, though exact timings remain unverified. For volume workflows (A/B testing hooks or product angles), even modest speed gains compound into more iterations per session.
How GPT Image 2 Fits a Video Content Pipeline
What makes a generated image “video-ready” for I2V animation
Image-to-video models inherit every artifact from the source image. Noise, inconsistent lighting, or color shifts get amplified over time. Higher-fidelity starting images (clean photorealism, accurate text, stable composition) produce smoother, more consistent motion.
If the reported improvements hold, GPT Image 2 outputs should serve as stronger foundations for I2V pipelines than GPT Image 1.5 currently does.
Product shots, scene starters, and social graphic templates
Three immediate use cases stand out:
Product shots for e-commerce ads: Generate lifestyle environments directly with accurate text overlays.
Scene starters for I2V: Create a high-quality static frame, then animate motion, camera moves, and temporal consistency in a separate tool.
On-screen text overlays: Accurate, multilingual text that drops straight into video without manual fixes.
Where the image-to-video handoff happens
GPT Image 2 (based on all available reports) is a still-image generator only. The workflow remains:
Generate high-quality image.
Export.
Feed into your chosen I2V model (up to 1080p, typical 5–15 second clips).
That handoff is not a limitation — it’s how every current high-quality short-form pipeline works today. Anyone claiming a single model will replace the entire image-to-video stack is describing a tool that hasn’t been announced.
What to Watch When It Officially Launches
API access and pricing: Current GPT Image 1.5 API pricing is documented on OpenAI’s developer site. Expect GPT Image 2 to launch at a premium that may decrease over time, as happened with previous models. Check the official OpenAI API models page on launch day.
Commercial use terms: Verify rights directly in the updated OpenAI Terms of Use before client work or paid campaigns.
Platform integration timeline: DALL·E 3 is scheduled for retirement on May 12, 2026. Migration to GPT Image 1.5 (and eventually 2) is already required for anyone on older endpoints.
Known Limitations Based on Early Testing
Still image-only: No native video or animation capabilities.
No confirmed release date: Community estimates point to May–June 2026, but OpenAI has not confirmed.
Prompt control remains approximate: Even with stronger adherence, precise camera geometry or timing still requires post-production tweaks in most video pipelines.
What to Do Right Now
Keep running your current GPT Image 1.5 → I2V workflow. It remains solid. The reported upgrades, if they ship as tested, will simply make the source images better — not obsolete the pipeline.
If you’re still on DALL·E 3 endpoints, migrate now. That deadline is fixed.
When the official launch drops, run your own test first: generate a social graphic with text overlays and a product lifestyle shot. That 15-minute check will tell you everything you need to know for short-form video work.
I’ll update this piece the moment OpenAI makes it official.
FAQ
Q: When will GPT Image 2 be released? No official date as of publication. Community estimates based on Arena testing timing and the DALL-E retirement deadline point to May–June 2026, but OpenAI hasn't confirmed anything. Worth checking regularly if you're planning around it.
Q: Can I animate GPT Image 2 images into video? Yes — through an I2V pipeline, not natively within GPT Image 2 itself. Generate the image, export it, then feed it into a separate image-to-video tool. The higher quality source image you start with, the cleaner the animation tends to be.
Q: Can GPT Image 2 outputs be used commercially? Probably yes, based on how OpenAI has handled previous models — but verify the specific terms when it launches. OpenAI permits commercial use of their image outputs, though purely AI-generated content may face limits on copyright protection, and terms should be reviewed before using outputs in paid commercial work.
Previous Posts:
Best Image to Video AI Tools for Creators
Free Image to Video AI: What Actually Works
Best AI Video Generators (2026)