O Que É o Gemini 3.1 Flash TTS? Um Guia Pra Quem Cria Vídeos

São 23h47 e estou na oitava geração do mesmo trecho de 30 segundos de locução. As sete primeiras soavam como um GPS mandando eu virar à esquerda. Essa finalmente tem uma pausa no lugar certo, uma risadinha onde o roteiro diz "ri", e uma mudança real de ritmo quando o produto entra em cena. Essa virada — de "voz de IA" pra algo que eu colocaria num short de verdade — é exatamente do que a gente vai falar aqui.
Se você viu o nome circulando desde 15 de abril e tá tentando entender se isso muda alguma coisa no seu fluxo de trabalho, a resposta curta é: sim, mas não do jeito que os posts de lançamento fazem parecer. Não é um botão mágico de "locução com um clique". É um narrador muito mais obediente, com 200+ comandos inline, 70+ idiomas, e um plano gratuito generoso o suficiente pra testar de verdade antes de se comprometer com qualquer coisa.
Aqui é a Mariana. Vou te mostrar o que mudou de verdade, onde encaixa num fluxo de short-form — e, mais importante, o que essa ferramenta ainda não consegue fazer. Testei desde a semana de lançamento com roteiros reais de clientes, não copy de demonstração, então os limites que vou apontar são os que você vai bater na prática.
O Que É o Gemini 3.1 Flash TTS?
O Gemini 3.1 Flash TTS é o modelo de text-to-speech mais recente do Google DeepMind, lançado em preview no dia 15 de abril de 2026. Ele está disponível via Gemini API, Google AI Studio, Vertex AI e Google Vids.
Em termos simples: você passa um roteiro, ele gera a locução — com muito mais controle do que antes, sem precisar de DAW.
Como se compara ao Gemini 2.5 Pro TTS e ao 2.5 Flash TTS?
Se você usou a família 2.5, o salto é maior do que o número de versão indica. A atualização do Gemini 2.5 TTS de dezembro de 2025 suportava 24 idiomas e lidava com diálogos de múltiplos locutores, mas controle de estilo era basicamente "escolha uma voz e torça." O 3.1 Flash TTS adiciona 200+ áudio tags, expande pra 70+ idiomas com sotaques regionais, e no leaderboard independente de TTS da Artificial Analysis, ele pontuou um Elo de 1.206 — segundo lugar geral, à frente do ElevenLabs v3.
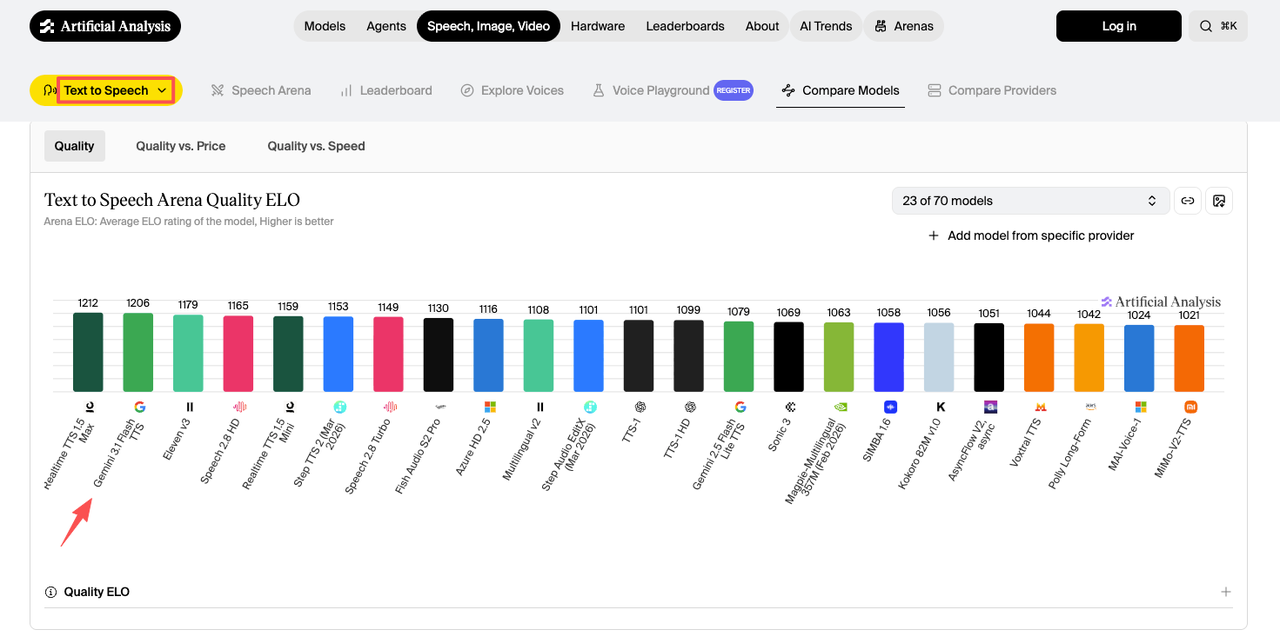
Sendo honesta: Elo de benchmark não significa nada até você ouvir o resultado. Mas a diferença entre 24 idiomas e 70+ é o tipo de coisa que muda quais projetos você consegue pegar.
3 Novidades Que Realmente Importam Pra Quem Cria Conteúdo
Áudio Tags (200+) — sussurros, risadas, ritmo e tom
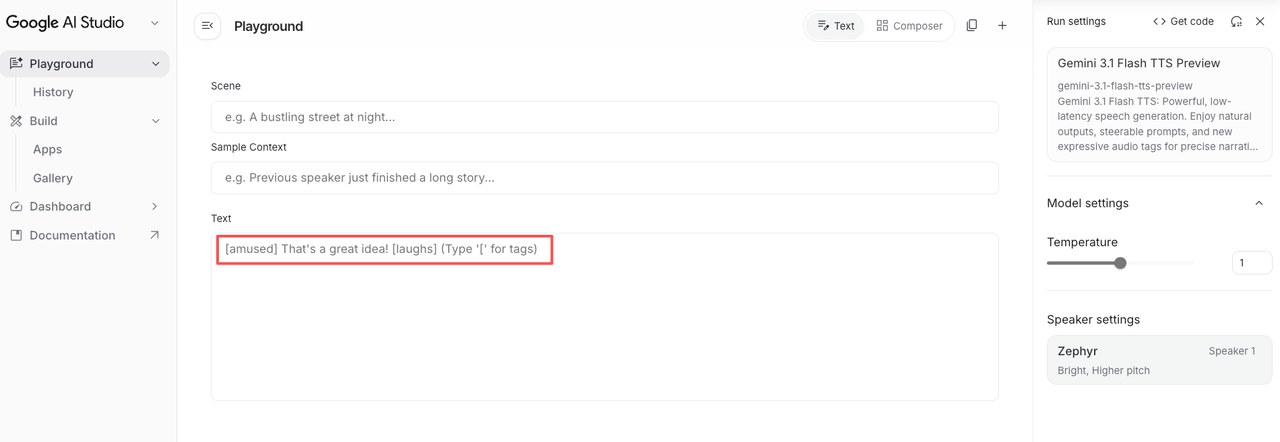
Essa é a atualização que justifica espaço num fluxo de trabalho real. Você embute os comandos diretamente no roteiro, entre colchetes:
[excited] Ok, essa é a parte que eu tava esperando pra mostrar pra você. [pause] [slower pace] Olha a diferença. [whispers] Ninguém tá falando disso.
O resultado realmente segue as tags. Não perfeitamente — "sarcástico" nas minhas três primeiras tentativas saiu mais como "levemente julgador" — mas bem o suficiente pra eu parar de dividir o roteiro manualmente em seções emocionais.
Pra short-form, as que uso quase todo dia:
pause antes de revelar um gancho
faster pace pra conteúdo em lista (economiza 3–5 segundos num clip de 30s, o que importa no TikTok)
whispers pro framing de "segredo/dica" que performa bem em conteúdo de afiliados
laughs — com moderação, porque risada falsa é pior do que nenhuma risada
Tem também templates de formato — narrador de podcast, âncora de notícias, agente de suporte, tutor de idiomas, guia de bem-estar — que funcionam como ponto de partida antes de você afinar com as tags. No Google AI Studio eu cronometrei: configurar uma voz e exportar as configurações como código de API leva cerca de 4 minutos. Depois disso, toda geração futura usa os mesmos parâmetros.
Diálogo de Múltiplos Locutores em uma Única Geração
Antes do 3.1, diálogo entre duas pessoas significava gerar cada voz separada e juntar na edição. Agora você escreve os dois locutores num único prompt e recebe uma conversa que soa natural de uma vez só.
Testei um bate-papo de 45 segundos (especialista vs. cético) e ficou utilizável na primeira tentativa — o que é raro.
Suporte Nativo a 70+ Idiomas (contra 24 no Gemini 2.5)
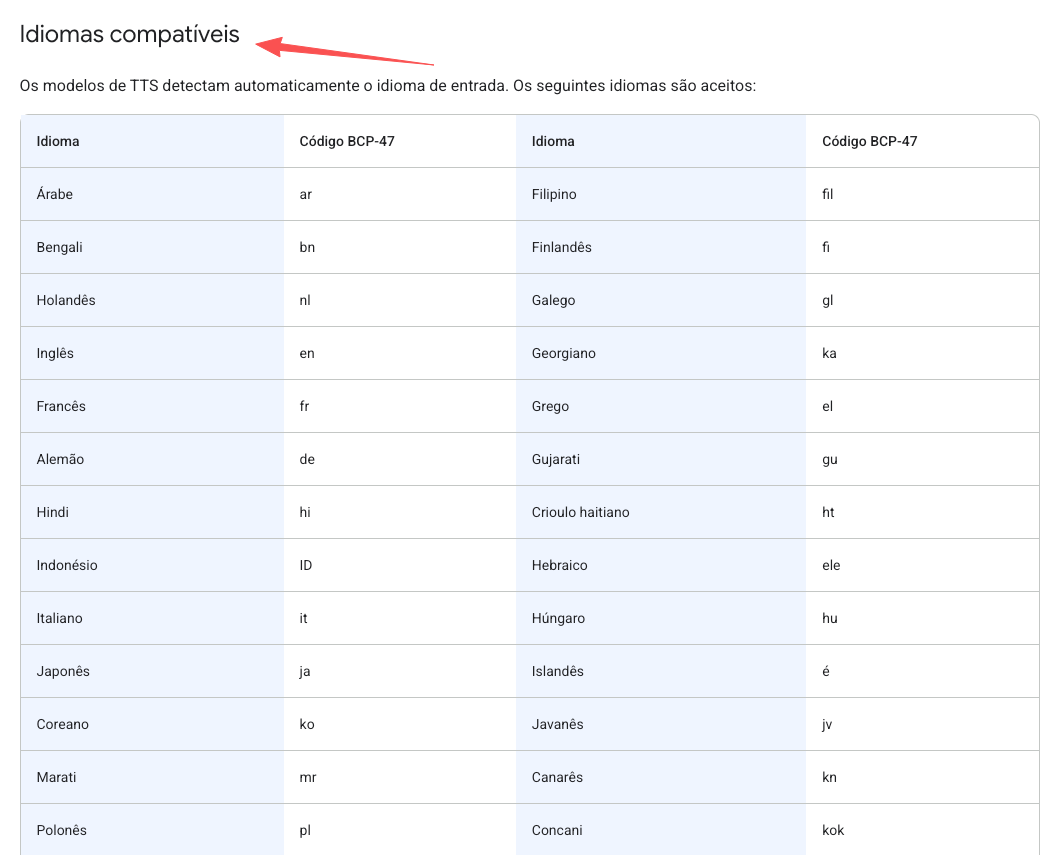
O salto de 24 pra 70+ idiomas é a maior atualização silenciosa. Cada idioma agora tem os mesmos controles de estilo e sotaque do inglês.
Pra inglês, dá pra escolher variantes regionais como Valley, Southern, RP, Brixton e Transatlantic.
Pra criadores multilíngues e equipes de e-commerce, isso elimina a necessidade de contratar atores de voz ou usar ferramentas separadas pra cada idioma.
Como o Gemini 3.1 Flash TTS Encaixa no Fluxo de Criação de Vídeo
Aqui vem o check de realidade. O Gemini 3.1 Flash TTS gera áudio. Só isso. Ele não gera vídeo, não corta footage, não trata legendas e não sabe em qual plataforma você vai postar.
Roteiro → Locução → Importar no Editor
Meu fluxo real funciona assim:
Escrevo o roteiro com as áudio tags inline — leva o mesmo tempo de um roteiro normal, talvez 30 segundos a mais por minuto de conteúdo
Gero no AI Studio ou via API — pra um short de 30 segundos, a geração leva menos de 10 segundos
Baixo o arquivo WAV e jogo no editor como camada de áudio
Adiciono footage, B-roll e legendas por cima — essa parte ainda é trabalho do editor
O número real de tempo economizado: um short faceless no YouTube que antes me tomava ~25 minutos pra gravar, editar e limpar o áudio, agora tem a etapa de locução em cerca de 4 minutos. Legendas, cortes e B-roll continuam levando o mesmo tempo de sempre.
Casos de Uso — Onde Isso Realmente Faz Sentido
Nem todo criador precisa disso. Os que mais se beneficiam:
Criadores de conteúdo faceless no YouTube/TikTok rodando vídeos de talking points, resumos ou explicações — sem estúdio, sem ator de voz
Equipes de e-commerce convertendo descrições de produto em vídeos de listing em múltiplos idiomas — o suporte a 70+ idiomas faz o trabalho pesado aqui
Criadores de afiliados testando múltiplos estilos de gancho — gera 5 variantes do mesmo roteiro com tags de tom diferentes, vê qual segura o watch time
Criadores talking-head que precisam de um narrador de reserva pra segmentos pesados de B-roll quando a própria locução foi interrompida ou precisa de retake
Se você faz trabalho cinematográfico, narrativa ou qualquer coisa onde a voz é o produto (apresentação de podcast, voz de marca como ativo de identidade), isso é uma ferramenta de apoio — não uma substituição.
O Que o Gemini 3.1 Flash TTS Ainda Não Faz
Vou falar isso claramente, porque a cobertura do lançamento passou por cima: esse é um modelo de geração de voz. Só isso.
Algumas coisas que ele não faz:
Gerar vídeo. Não tem saída visual. Você ainda precisa de footage, clipes de stock ou conteúdo baseado em imagem.
Sincronizar lábios com footage existente. Se você tem um clip talking-head e quer trocar o áudio, o 3.1 Flash TTS te dá o áudio novo — mas você vai precisar de uma ferramenta separada pra sincronizar os lábios.
Clonar sua voz a partir de uma amostra. Apesar do que algumas coberturas de terceiros afirmaram na semana de lançamento, a documentação oficial do Google lista 30 vozes pré-definidas e não oferece clonagem de voz pública nesse preview. Estou marcando isso porque vi a afirmação de "clonagem de voz" em alguns artigos e não bateu com o que encontrei na documentação.
Fazer dublagem. Se você tem um vídeo em espanhol e quer uma versão em português, o 3.1 Flash TTS gera o áudio em português — mas não traduz nem alinha ao timing original.
O Que Você Ainda Precisa Pra Terminar um Short Publicável
Um stack realista pra um vídeo short-form:
Roteiro — seu cérebro, ou um LLM
Locução — Gemini 3.1 Flash TTS, o que esse artigo cobre
Footage / B-roll — seus próprios, stock, ou vídeo generativo
Legendas — toda plataforma quer elas queimadas no vídeo
Cortes, ritmo, adaptação de plataforma — crop 9:16, posicionamento do gancho, framing do CTA
A etapa de locução costumava ser uma das mais lentas. Agora é uma das mais rápidas. O que significa que o gargalo mudou de lugar — pra edição, legendagem e teste de variantes. Essa parte ainda é por sua conta.
Todos os outputs vêm com marca d'água SynthID, um sinal inaudível que identifica o áudio como gerado por IA. Pra maioria dos casos de uso de criadores isso não afeta nada — quem ouve não percebe e o sinal sobrevive à compressão normal — mas se você atua em áreas reguladas (jornalismo, conteúdo político, certas plataformas de anúncio), vale saber.
FAQ
O Gemini 3.1 Flash TTS é gratuito? Tem um plano gratuito que realmente dá pra usar pra testar — não são 30 segundos de demo seguidos de paywall. O plano pago, conforme a documentação de preços da Gemini API, é $1 por milhão de tokens de texto de entrada e $20 por milhão de tokens de áudio de saída. Um modo batch oferece 50% de desconto. Pra ter noção: gerar uma locução de 30 segundos custa frações de centavo no plano pago. Dados de uso do plano gratuito podem ser usados pra melhoria do produto — vale saber se você trabalha com roteiros de clientes sensíveis.
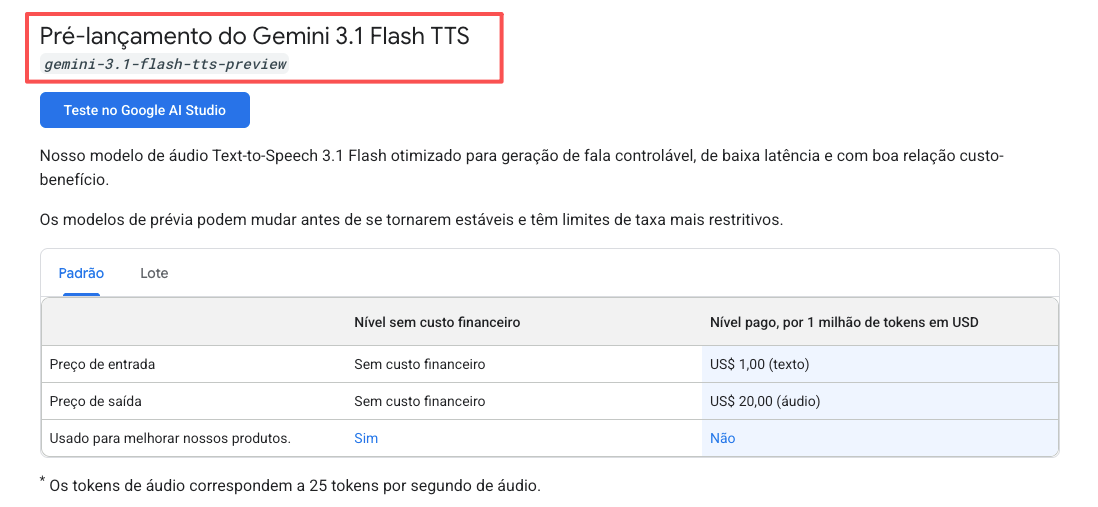
O que aconteceu com o Gemini 2.5 Pro TTS? Ainda disponível, ainda na API. O Google não descontinuou. Se você já tem pipelines rodando no 2.5, continuam funcionando. Pra projetos novos, o 3.1 Flash TTS é a recomendação padrão — mais expressividade, mais idiomas, mais controle, custo por token menor.
Ele suporta clonagem de voz? Não no preview público. São 30 vozes pré-definidas, variantes de sotaque regional, parâmetros de estilo — mas sem "clonar a partir de uma amostra de 30 segundos" na documentação oficial do Google no momento em que escrevo isso. Esse ponto estou monitorando porque o comportamento das ferramentas muda com as atualizações.
Conclusão
O Gemini 3.1 Flash TTS é a primeira ferramenta de TTS que eu usaria pro meu próprio conteúdo, não só pra trabalho de cliente. As áudio tags são o motivo — conseguir escrever pausas e sussurros diretamente no roteiro transforma o que eram várias etapas em uma só.
Mas é só uma ferramenta de locução. Sem vídeo, sem legendas, sem otimização de plataforma. Você ainda precisa editar, formatar e testar todo o resto.
Se você produz conteúdo short-form em alto volume, vale testar. Se você faz um vídeo polido por mês e sua voz é parte da sua marca, sua própria voz ainda ganha.
Você usa alguma ferramenta de TTS hoje em dia? Me conta nos comentários qual voz você acha mais natural — quero comparar com o que estou testando aqui.
Leituras Recomendadas
Softwares de edição pra Shorts que realmente valem o tempo
LTX 2.3 Áudio para vídeo: crie retratos falantes e clipes com voz real
Melhor gerador de vídeo com IA gratuito: 10 ferramentas que valem o teste