Como Usar o Gemini 3.1 Flash TTS pra Fazer Locução de Vídeo

Entrei bem desconfiada. Mais um modelo de TTS, mais um lançamento de "voz de IA que finalmente soa humana" — já ouvi isso algumas vezes. Mas as audio tags me chamaram atenção. Não porque o Google disse que eram expressivas. Mas porque pareciam algo que eu conseguia colocar direto no roteiro e controlar, no meio de uma frase, sem passar o clipe por uma segunda ferramenta.

Então passei uma semana rodando os mesmos três roteiros de locução — um demo de produto, uma intro talking-head, um ad read de 30 segundos — e comparando com o que eu uso normalmente. Aqui está o que descobri sobre como usar isso de verdade pra vídeo, não o que a página de vendas promete.
O Que Você Precisa Antes de Começar
Google AI Studio vs acesso via API
Pra 90% dos criadores de conteúdo short-form, o Google AI Studio é a porta certa. Gratuito, sem código, você cola o roteiro, escolhe uma voz, clica em gerar e baixa o arquivo. Só isso.
A API do Gemini existe se você quer fazer em lote — tipo, gerar locuções pra 40 vídeos de produto num único script. Mas se você faz um vídeo por vez, a interface do Studio é mais rápida do que configurar chaves de autenticação. O preço da API é por caractere de texto de entrada, o que importa em escala — mas é basicamente irrelevante pra locuções avulsas.
Seu roteiro e o idioma-alvo
Duas coisas pra preparar antes de tocar na ferramenta:
Um roteiro limpo — as palavras exatas que você quer que sejam faladas, sem direções de cena misturadas nas falas (a gente adiciona isso como tags daqui a pouco)
Uma escolha de idioma — o modelo cobre mais de 70 idiomas, mas as audio tags em si são só em inglês. Dá pra combinar tags em inglês com roteiro em outro idioma, o que é útil — mas vale saber antes
Uma coisa que a documentação não enfatiza: a janela de contexto de entrada é de 16K tokens pra TTS. Cerca de 12.000 palavras de roteiro numa única geração. Mais do que suficiente pra short-form. Se você estiver fazendo um capítulo de audiobook, aí sim divide em partes.
Passo 1 — Escreva o Roteiro Com Audio Tags
Como as audio tags mudam o resultado (demo rápido)
Versão sem tag:
"Testei essa ferramenta por uma semana. Os resultados me surpreenderam."
Versão com tag:
"[thoughtful] Testei essa ferramenta por uma semana. [short pause] [with slight surprise] Os resultados me surpreenderam."
Rodei os dois na mesma voz, mesmas configurações. A versão sem tag lê bem — neutra, limpa, flat. A com tag pausa de verdade depois de "semana", e a segunda frase tem uma pequena elevação, como alguém reconsiderando levemente o que acabou de dizer. Essa é a diferença.
As tags são modificadores entre colchetes inseridos direto no seu texto. O modelo lê como instruções de performance, não como palavras pra falar. O modelo de fala expressiva do Google vem com mais de 200 audio tags disponíveis.
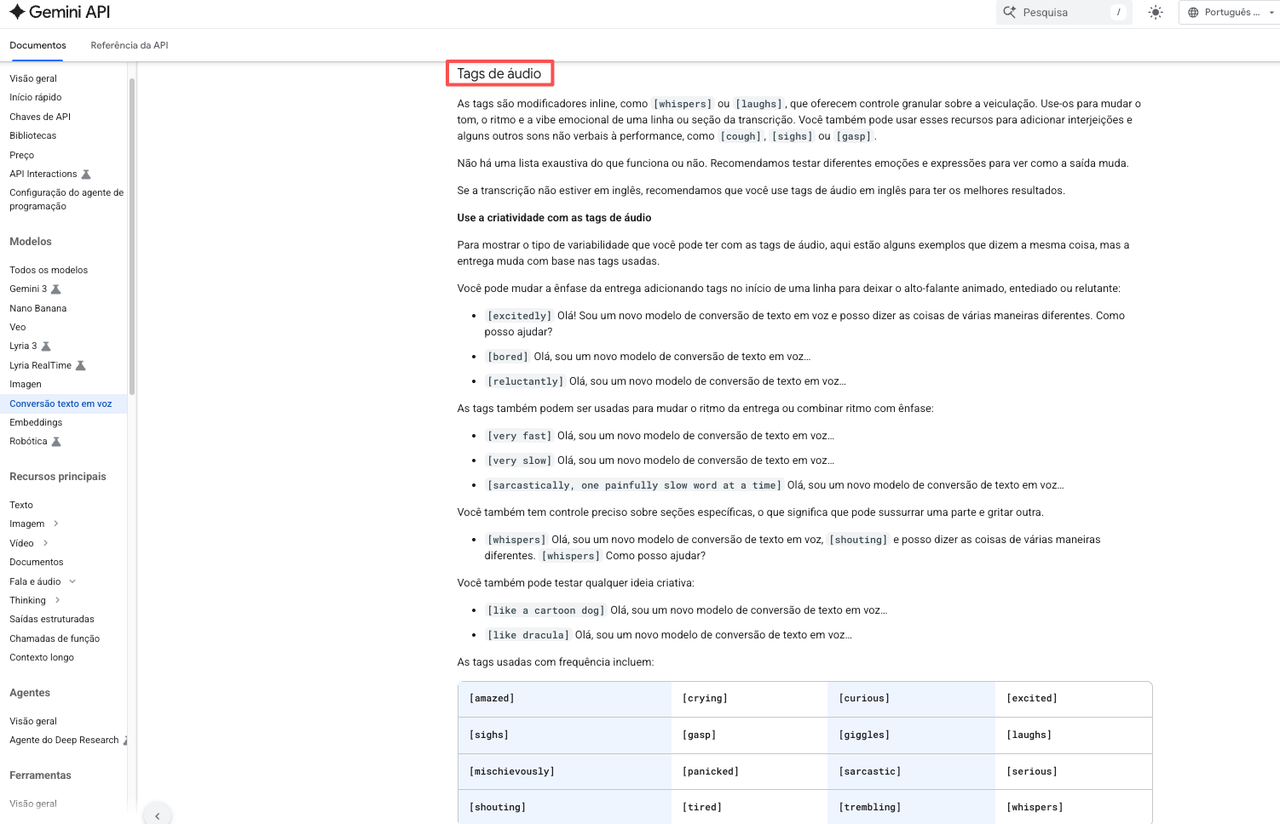
Tags que criadores de conteúdo realmente usam
Depois de uma semana testando, essas foram as que eu mais usei:
[pause] ou [short pause] — controla ritmo. A tag mais útil de todas.
[whispers] — pra linhas de gancho, revelações, tudo que pede intimidade
[enthusiasm] / [excitedly] — aberturas em ads e vídeos de hype
[thoughtful] — pra momentos de reflexão, reviews, "o que aprendi com isso"
[laughs] / [sighs] — textura não-verbal. Usar com moderação.
[neutral] — reseta depois de uma tag de emoção pra a linha seguinte não carregar o tom
O restante das 200 tags existe e dá pra explorar com coisas como [urgent] ou [cautious]. Mas, na real, 80% do trabalho de locução que fiz veio desses seis acima.
Quando ficar com texto simples
Tags viram armadilha se você exagera. Cometi esse erro no segundo dia — tagueei uma frase sim, uma não, e o resultado pareceu uma radionovela. Atuação demais.
Não use tags quando:
A linha é exposição neutra — funcionalidades de produto, passos, instruções
Você está fazendo uma leitura longa (+30 segundos) onde consistência de tom importa mais que variação
O prompt de cena já define o clima
A pontuação já cria pausas naturais — vírgulas e pontos já cuidam de boa parte do ritmo. Tags são pra momentos específicos: uma risada, um sussurro, uma batida de surpresa. Não pro roteiro inteiro.
Passo 2 — Gere a Locução no Google AI Studio
Escolhendo entre as vozes
São 30 vozes pré-configuradas, cada uma com personalidade distinta. Não dá pra fazer upload de clone de voz aqui — é biblioteca padrão. Algumas se destacaram pra mim:
Kore — quente, clara, registro médio. Meu padrão pra talking-head.
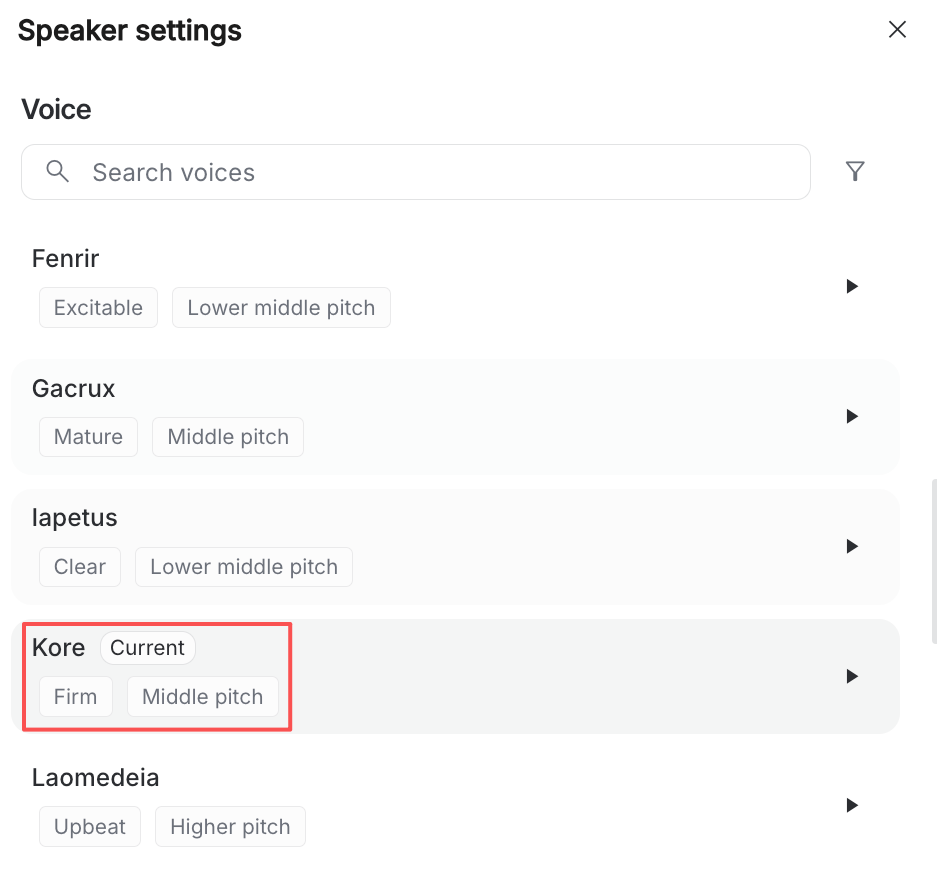
Charon — mais grave, autoritária. Boa pra demos de produto, péssima pra ads de hype.
Puck — mais leve, brincalhona. Funcionou bem pra ganchos nativos de TikTok.
Aoede — voz HD, mais clareza. Usei quando o áudio seria o elemento principal (sem trilha sonora).
Teste 4 ou 5 numa linha de teste antes de decidir. Vozes respondem diferente à mesma tag — o [enthusiasm] do Charon não é o [enthusiasm] do Puck.
Preview, regenerar e exportar MP3 ou WAV
O fluxo dentro do AI Studio:
Cole seu roteiro tagueado
Escolha voz e idioma
Gere — normalmente leva alguns segundos pra clipes curtos
Ouça no navegador
Se alguma coisa soar estranha, regenere antes de mexer no roteiro. Às vezes é o modelo, não a escrita.
Exporte — MP3 pra web, WAV pra edição
Eu regenerei cerca de um a cada três takes no começo. No final da semana, um a cada oito. Você fica mais rápido pra escrever prompts que o modelo entende.
Passo 3 — Configure Diálogo Multi-Speaker (Opcional)
Quando multi-speaker importa pro seu conteúdo
Pula essa parte se você faz narração solo.
Importa se você está fazendo:
Clipes estilo podcast a partir de roteiro
Diálogos de dois personagens em ads ("amigo A recomendando pra amigo B")
Esquetes em formato de entrevista
Bate-volta educativo
Regras de formato que reduzem gerações com erro
O formato conforme a documentação oficial de geração de fala da API do Gemini é rígido:
Joe: Cara, fiquei de queixo caído com esse modelo novo. Jane: É né?! Isso muda o jogo.
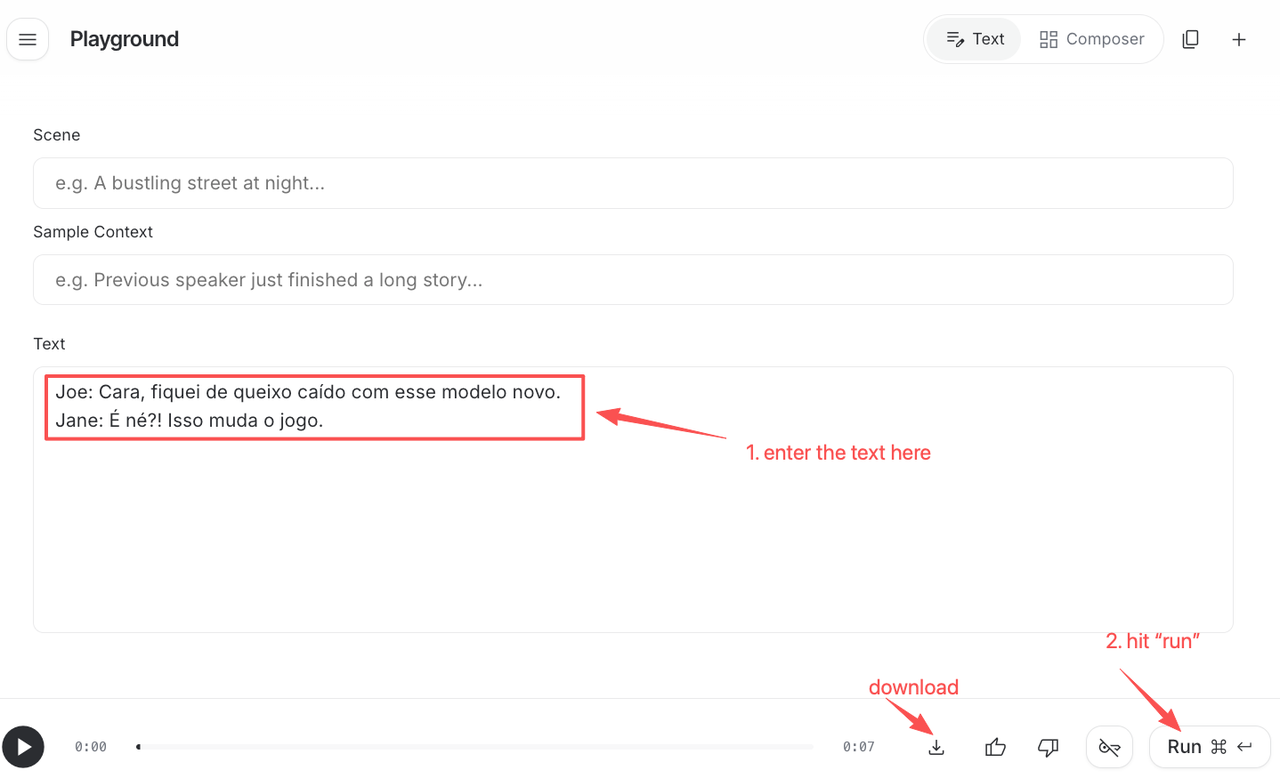
Nome do speaker, dois-pontos, fala. Cada speaker recebe uma voz na configuração. Duas regras do meu teste:
Mantenha os nomes dos speakers consistentes ao longo do roteiro inteiro. "Joe" e "joe" confundem o modelo.
Não misture linhas tagueadas com não-tagueadas aleatoriamente. Ou tagueia a maioria ou nenhuma. Misturado soa irregular no resultado.
O limite atual é dois speakers por geração. Se precisar de três, você gera em partes e monta.
Passo 4 — Importe o Áudio no Seu Fluxo de Vídeo
Sincronizando locução com os cortes
Baixa o arquivo. Joga no seu editor — CapCut, DaVinci Resolve, Premiere, tanto faz. Trata como qualquer outra faixa de voz.
Uma coisa que eu faço: gero a locução primeiro, depois corto o vídeo pra se encaixar no áudio. A locução tem ritmo natural embutido (pelas tags e pontuação), e brigar com esse ritmo na edição é trabalho jogado fora. Deixa o VO guiar os cortes. Mais rápido toda vez.
Gerando legendas automáticas a partir do áudio
Qualquer que seja a função de legenda automática do seu editor — usa. Locuções geradas por IA transcrevem limpo porque não tem ruído de fundo nem dicção estranha. A precisão nos meus testes ficou perto de 100%, mais alto do que a minha própria voz consegue pelo mesmo recurso.
Exportando pra TikTok, Reels e Shorts
Nada de especial aqui. Exporta MP4, 9:16, garante que os níveis de áudio estão normalizados — locução chegando mais alta do que a trilha de fundo é o erro mais comum de quem está começando. As plataformas comprimem o áudio forte no upload, então master alguns dB mais alto do que você acha que precisa.
Erros Comuns e Como Corrigir
Locução parece robótica — problema de posicionamento de tag
Geralmente significa poucas tags, ou tags só no começo. Coloca onde a emoção realmente muda. Uma linha como "Testei isso por uma semana e os resultados me surpreenderam" precisa da tag perto de "surpreenderam", não lá no começo.
Output muito rápido ou muito lento
Adiciona tags [short pause] ou [pause] manualmente. Ou ajusta a pontuação — vírgulas e pontos criam pausas naturais. Às vezes só mudar uma vírgula por um ponto já desacelera o suficiente.
Sotaque errado ou deriva de idioma
Seja explícita na configuração. Se você precisa de um sotaque regional específico, nomeia nas notas do diretor ou no prompt de cena — o alinhamento do prompt de estilo, o conteúdo do texto e as tags precisam apontar pra mesma direção. Um sotaque carioca precisa de texto em português brasileiro, não em inglês com expressões americanas.
Conclusão
Leva com um grão de sal — é uma semana de teste, e o modelo ainda está em preview, então o comportamento vai mudar. Mas o resumo curto: as audio tags são o primeiro recurso de TTS em muito tempo que mudou de verdade como eu escrevo locução, não só como eu gero.
O fluxo que funcionou pra mim: escrevo o roteiro no bruto, leio em voz alta, marco os pontos onde eu naturalmente pausaria ou mudaria o tom — e aí converto essas marcas em tags. Gero. Escuto. Regenero a linha que ficou estranha, não o roteiro inteiro.
Se você paga por uma ferramenta de voz e a única coisa que ela faz melhor é clonagem de voz, vale testar essa pra tudo mais. Se você precisa de voz clonada, mantém o que tem e usa essa pro resto.
Uma etapa manual a menos por vídeo. Todo dia. Isso acumula.
Você usa locução de IA no seu fluxo? Me conta nos comentários qual ferramenta está no seu setup agora — quero comparar com essa nas próximas semanas.
FAQ
Preciso saber programar pra usar audio tags? Não. Tags são só texto entre colchetes dentro do seu roteiro.
[whispers] Você não vai acreditar nisso.O resultado funciona com qualquer editor de vídeo? Sim. MP3/WAV são universais. Um detalhe: todo áudio gerado pelo modelo carrega uma marca d'água SynthID — imperceptível pra quem ouve, não afeta a qualidade, mas está lá.
Quais formatos de áudio o Gemini 3.1 Flash TTS exporta? MP3 e WAV pelo AI Studio. Via API, você também consegue OGG. O modelo por baixo gera PCM a 24kHz — ótimo pra todo uso em vídeo short-form.
Leituras Recomendadas
O melhor gerador de roteiros com IA pra criar conteúdo mais rápido