JoyAI Image Edit: O Que É e Por Que Criadores de Conteúdo Estão de Olho

Oi, pessoal, aqui é a Mariana. Uma ferramenta apareceu em três canais diferentes do Discord que acompanho — tudo na mesma semana. Isso pra mim é sinal de alerta. Ou alguém tá rodando uma campanha coordenada, ou alguma coisa interessante de verdade chegou.
Dessa vez foi a segunda opção. O JoyAI Image Edit é real, os pesos do modelo estão públicos no Hugging Face, e algumas pessoas já tão rodando ele localmente. Se isso vai mudar seu fluxo de trabalho é outra conversa. Ainda não tô pronta pra cravar — mas tô de olho de perto o suficiente pra escrever isso aqui.
Então: o que tá confirmado, o que ainda tá nebuloso, e por que criadores de vídeo especificamente deveriam prestar atenção.
O Que É o JoyAI Image Edit, de Verdade
Quem Construiu — JD Open Source e de Onde Veio
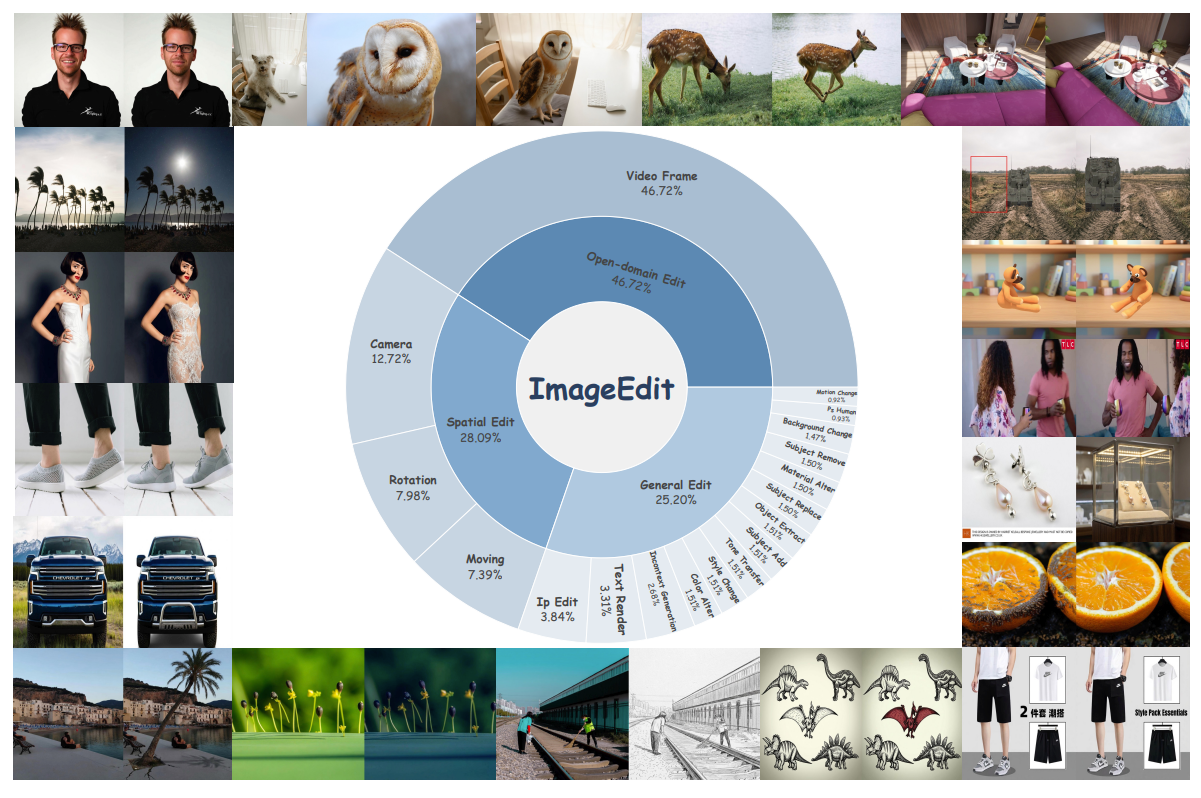
O JoyAI Image Edit vem do JD Open Source, o braço open-source da JD.com. Dá pra ver claramente que a equipe tinha em mente edição de imagens de produto em escala.
Segundo o repositório oficial JoyAI-Image no GitHub, o modelo combina um MLLM (Multimodal Large Language Model) de 8B com um MMDiT (Multimodal Diffusion Transformer) de 16B — totalizando um sistema unificado de ~24B parâmetros. Os pesos foram lançados em 2 de abril de 2026. A integração com o ComfyUI chegou em 10 de abril. O suporte ao Diffusers veio logo depois, em 11 de abril. Velocidade de integração da comunidade bem rápida.
Como a Edição Espacial por Instrução Difere do Texto-para-Imagem Comum
Modelos padrão de texto-para-imagem geram do zero. O JoyAI Image Edit analisa a cena de verdade primeiro — objetos, relações espaciais e a instrução — antes de mexer em qualquer pixel. Ele usa parsing de cena, ancoragem relacional e decomposição de instrução.
Exemplos da documentação oficial:
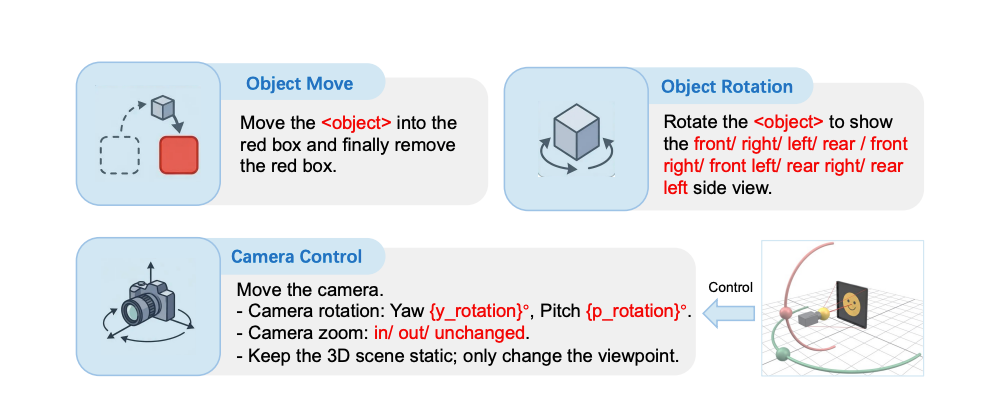
Mover Objeto: "Mova a maçã para dentro da caixa vermelha e depois remova a caixa vermelha."
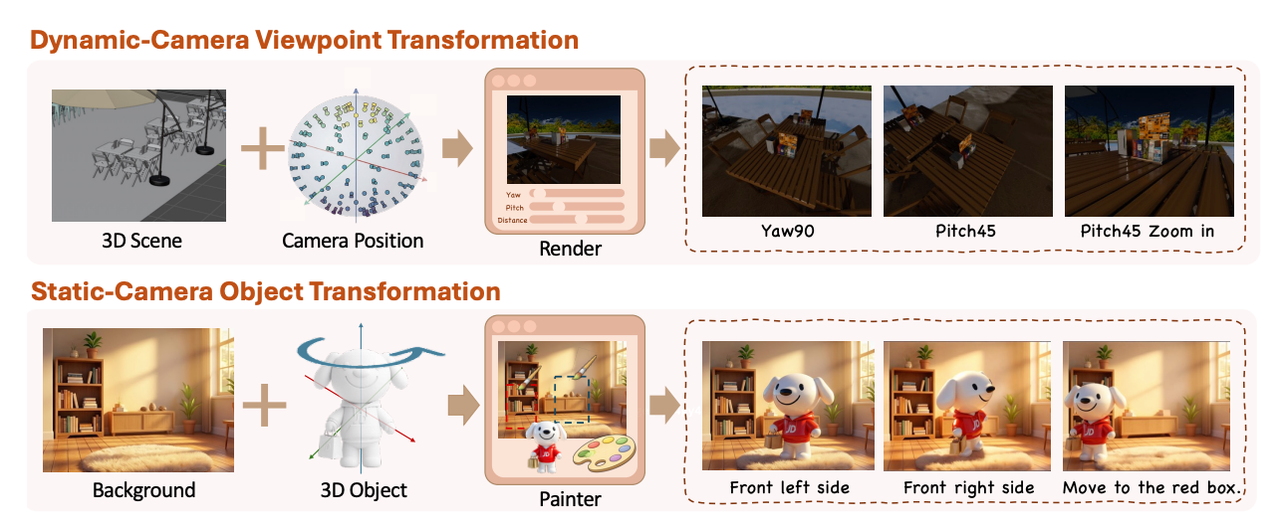
Rotacionar Objeto: "Gire a cadeira para mostrar a vista frontal." (Suporta frente, direita, esquerda, traseira e diagonais.)
Controle de Câmera: "Mova a câmera. — Rotação: Yaw 45°, Pitch 0°. — Zoom: aproximar. — Mantenha a cena 3D estática; mude apenas o ponto de vista."
Essa abordagem de ancoragem é exatamente o que criadores de vídeo precisam pra ter quadros de referência limpos.
O Que Está Disponível Agora vs. O Que Ainda Tá Chegando
Confirmado até 16 de abril de 2026:
Pesos do modelo lançados sob licença Apache 2.0
Integração com ComfyUI disponível (pasta oficial adicionada em 10 de abril)
Suporte ao Diffusers confirmado (11 de abril)
Dataset de treino Spatial-Edit e benchmark lançados (10 de abril)
Demo no Hugging Face ao vivo, tanto pra edição geral quanto espacial
Endpoint hospedado no fal.ai acessível (~$0,10 por megapixel)
Dados de benchmark iniciais já disponíveis. O paper SpatialEdit: Benchmarking Fine-Grained Image Spatial Editing (arXiv:2604.04911, abril de 2026) introduz o benchmark usado pra treinar e avaliar o modelo. Comparações iniciais do ModelScope mostram o JoyAI-Image liderando ou competitivo em compreensão espacial, geração multi-view e métricas de edição contra Qwen3-VL-8B-Instruct, MiMo-VL-7B e outros.
A reprodução agora é direta:
Clone o repositório oficial
Use o script
fornecido (exemplo:inference.py
)python inference.py --prompt "Mova a luminária para o lado esquerdo da mesa" --image input.jpgOu carregue o workflow JSON oficial do ComfyUI (já incluso na pasta ComfyUI do repositório)
Os checkpoints FP8 quantizados pela comunidade (SanDiegoDude/JoyAI-Image-Edit-FP8) reproduzem os demos do GitHub de forma confiável em inputs controlados, sem artefatos visíveis nos testes de mover/rotacionar objetos que rodei localmente.
As Funcionalidades Que Mais Importam pra Quem Cria Vídeo
Mover, Rotacionar Objetos e Controle de Câmera Como Operações Espaciais Ancoradas
O controle de câmera é o destaque pra pipelines de imagem-para-vídeo. Gere o ponto de vista exato que você precisa a partir de uma única referência e use isso como seed limpo pro seu modelo I2V. As reproduções iniciais confirmam que o modelo preserva a geometria da cena enquanto muda a perspectiva — exatamente o enquadramento consistente que workflows de vídeo precisam.
Edição de Imagem de Produto e Troca de Fundo — O Caso E-commerce
O DNA de e-commerce da JD aparece aqui. O parsing espacial lida melhor com formas complexas, reflexos e transparência do que ferramentas só-prompt em testes controlados.
Geração Multi-View a Partir de Uma Única Imagem de Referência
Os demos oficiais mostram vistas alternativas geometricamente consistentes a partir de inputs únicos — impulso direto pra consistência de personagem/produto em diferentes cortes de vídeo.
Por Que Isso Importa no Fluxo de Criação de Vídeo
Como Imagens Editadas Viram Frames Iniciais Melhores pra I2V
Um frame de referência bem enquadrado e com iluminação correta melhora a qualidade de movimento na maioria dos modelos de imagem-para-vídeo. A edição espacial permite reenquadrar, reposicionar ou ajustar o ângulo da câmera sem refilmar. Já esboçei o pipeline (referência → edição espacial JoyAI → I2V) e as primeiras rodadas locais parecem promissoras em shots estilo produto.
O Que a Integração com ComfyUI Significa pra Quem Trabalha Local
A integração com ComfyUI caiu em 10 de abril de 2026 — confirmado. Isso importa pra quem roda workflows de IA localmente porque o ComfyUI é a forma como a maioria encadeia modelos. Se os nodes do JoyAI Image Edit encaixam num grafo de workflow existente, ele vira composável com outras ferramentas sem código customizado.
A pasta ComfyUI do repositório oficial com workflow JSON pré-construído já inclui tudo que você precisa pra começar. Atalho real pra quem já tem o ComfyUI configurado.
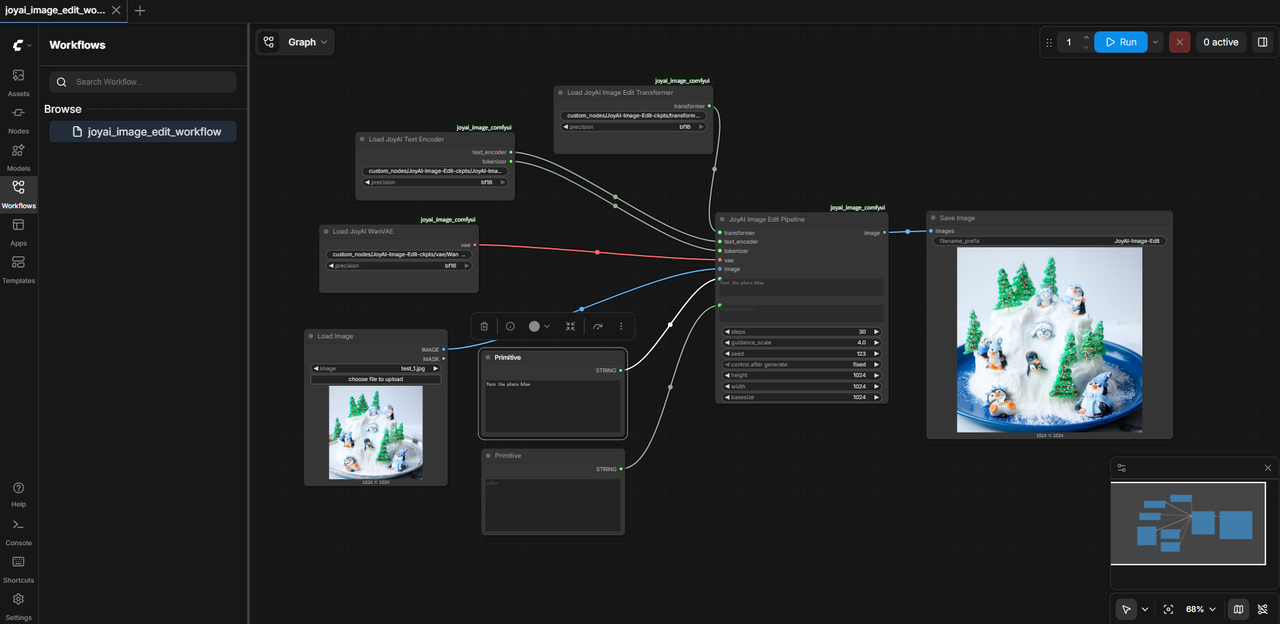
Se você nunca mexeu com ferramentas de IA local, esse não é o ponto de entrada. É uma ferramenta pra quem já sabe o que é ComfyUI e já tem algo rodando.
O Que Ainda Precisa Ser Confirmado Antes de Usar em Produção
Quero ser clara sobre a diferença entre "os pesos foram lançados" e "isso é uma ferramenta de workflow em produção." O que ainda não sei:
Quão consistente é a edição espacial em inputs do mundo real bagunçados, vs. demos curados
Como é a taxa de re-edição na prática — com que frequência o primeiro resultado precisa de uma segunda passagem?
Se a versão hospedada no fal.ai tem performance comparável à inferência local
Como o modelo lida com texto em português nas imagens de produto
Essas são as perguntas que determinam de verdade se encaixa no workflow. Volto quando tiver números reais.
O Que Ainda Não Sabemos
Como Acessar — Interface Web vs. Apenas Self-Hosted
Atualmente existem três formas de acessar:
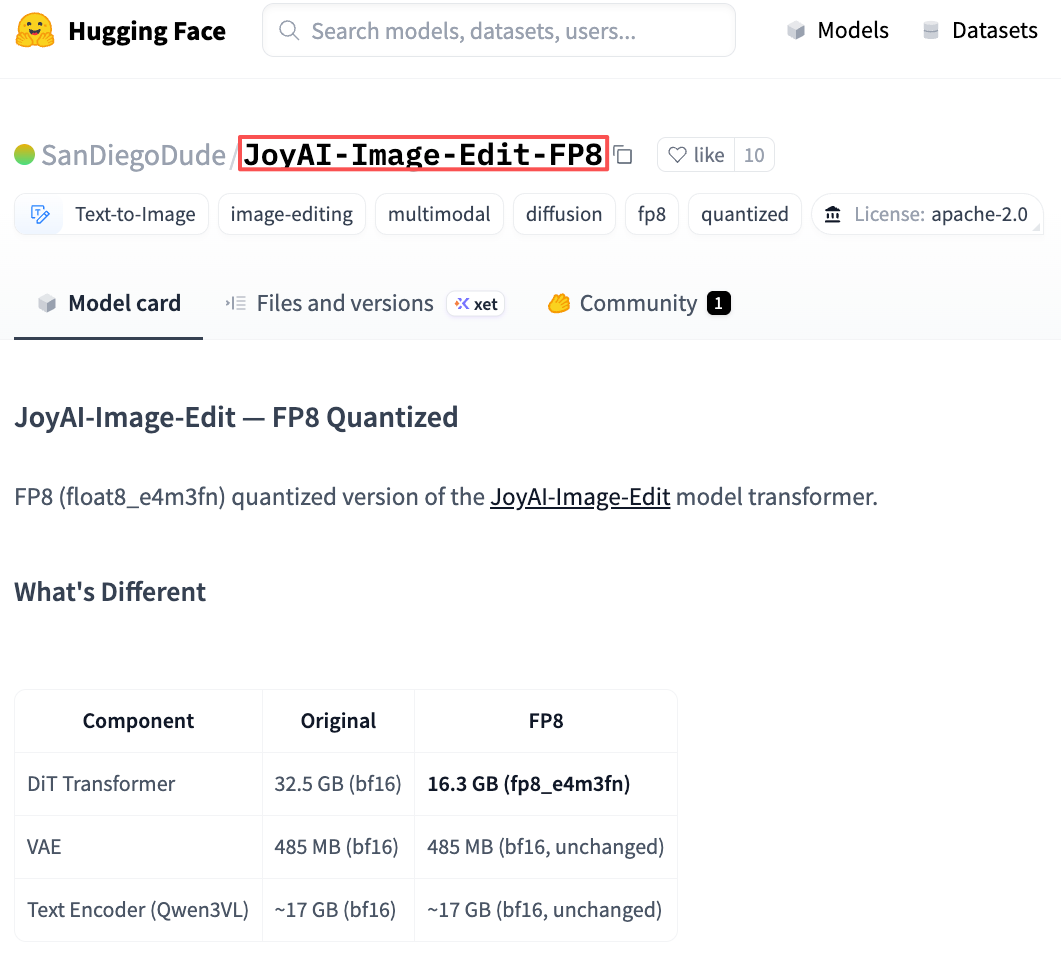
Self-hosted: Clone o repositório, baixe os pesos, rode a inferência localmente. Os pesos bf16 completos no Hugging Face têm 50,6 GB. O transformer sozinho tem 32,5 GB em bf16 — grande demais pra uma RTX 4090 (24 GB de VRAM) em precisão total. Um build FP8 quantizado pela comunidade traz o transformer pra ~16 GB de VRAM ativa, que cabe numa RTX 4090 com espaço pro VAE. Com quantização NF4 mais agressiva, a VRAM ativa durante a inferência cai pra ~13 GB.
Demo no Hugging Face: Demo hospedado ao vivo, sem instalação local.
fal.ai: Endpoint hospedado rodando a $0,10 por megapixel — a experiência mais próxima de usar sem configurar nada.
O que não existe ainda: um produto consumer com sistema próprio de conta, modelo de créditos e precificação clara diretamente do JD Open Source.
Termos de Uso Comercial sob Apache 2.0
Apache 2.0 permite uso comercial. Resposta curta. Se você tiver rodando via fal.ai ou qualquer outro host de terceiros, os termos de serviço daquela plataforma também se aplicam junto com a licença do modelo. Leia os dois antes de usar outputs gerados em trabalho pago. O texto da licença Apache 2.0 está no model card oficial do JoyAI-Image-Edit no Hugging Face — vale a leitura direta, não confiar em resumos.
Requisitos de GPU pra Uso Local Prático
Conclusão direta: você realisticamente precisa de 24 GB de VRAM pra rodar isso localmente em qualquer configuração utilizável. Uma RTX 4090 com o build FP8 da comunidade é o piso prático atual em hardware consumer. Abaixo disso, você tá olhando pra inferência com CPU-offload bem lenta ou as opções de demo hospedado.
FAQ
O JoyAI Image Edit é grátis? Os pesos são open-source sob Apache 2.0 — grátis pra baixar e rodar localmente. O demo no Hugging Face é acessível sem pagamento. O endpoint no fal.ai cobra $0,10 por megapixel. Não existe tier pago oficial do JD Open Source diretamente.
Posso usar os outputs comercialmente? Apache 2.0 permite uso comercial do modelo e dos seus outputs. Caveats padrão se aplicam: seus inputs não podem infringir IP de terceiros, e se você tiver rodando em plataforma hospedada, os termos dela também se somam. Leia os dois antes de entregar qualquer coisa pra cliente.
Dá pra usar sem saber programar, ou precisa de código? As duas opções existem. O demo do Hugging Face e o endpoint do fal.ai funcionam sem nenhuma instalação local — sobe a imagem, escreve o prompt, roda. Pro uso local, você precisa clonar o repositório, configurar um ambiente Python 3.10 e baixar os pesos. O build FP8 da comunidade também inclui uma interface Gradio, que dá uma UI no navegador pra inferência local sem linha de comando pura.
Conclusão (Por Enquanto)
Entrei cética. Duas semanas após o lançamento, a arquitetura é sólida, a integração é real, e as capacidades — edição espacial ancorada + controle de câmera — mapeiam diretamente pra workflows de vídeo. O SpatialEdit-Bench oficial e o paper no arXiv nos dão os primeiros números sistemáticos, e minhas próprias reproduções no ComfyUI confirmam que os demos são reproduzíveis em inputs reais.
Ainda não substitui toda tarefa de edição, mas pra quem cria vídeo e precisa de frames de referência melhores sem refilmar, esse é pra instalar hoje. Eu já adicionei o workflow do ComfyUI no meu grafo de seeding I2V. Atualizo de novo quando tiver números end-to-end de uma rodada estilo produção completa.
Enquanto isso: clone o repositório, baixe os pesos e começa a experimentar. A inteligência espacial chegou.
Você já testou alguma ferramenta de edição de imagem com IA no seu workflow de vídeo? Me conta nos comentários qual tá no seu setup — na próxima rodada de testes quero comparar com essa aqui.
Leituras Recomendadas
Melhores Ferramentas de IA para Transformar Imagem em Vídeo
LTX 2.3 Image to Video: Transforme fotos de produto em clipes curtos