Gemini 3.1 Flash TTS vs ElevenLabs for Short-Form Video

Hey everyone, Dora here. I had four tabs open last Tuesday night. Same script — a 45-second UGC hook for a skincare client. One tab running ElevenLabs on Creator. One running Gemini 3.1 Flash TTS in Google AI Studio. Two more running older TTS tools I won't name because they lost before the stopwatch even started.
By midnight I had a spreadsheet, 38 generated clips, and a conclusion I didn't expect.
If you're producing 5+ short-form videos a day and you're trying to decide which of these two to commit to — I'll save you the three hours I just burned. The answer isn't "whichever sounds better." Both sound good now. The answer depends on exactly three things: whether you need to clone a voice, whether you batch-produce in multiple languages, and how much audio you generate per month.
Here's the breakdown.
Gemini 3.1 Flash TTS vs ElevenLabs at a Glance
Aspect | Gemini 3.1 Flash TTS | ElevenLabs |
Launch / Status | Preview, April 15, 2026 | Production, mature (since 2022) |
Voice quality (Elo) | 1,206 on the Artificial Analysis TTS Leaderboard (2nd overall) | Historically #1; still strong on raw English naturalness |
Voices available | 30 prebuilt | Large voice library + voice design |
Voice cloning | No | Yes — instant (Starter+) and professional (Creator+) |
Languages | 70+ | |
Control method | 200+ audio tags + natural language prompts | Voice design, stability/similarity sliders, emotion via model |
Pricing (input) | $1 per million text tokens | Credit-based ($0.10–$0.50 per minute depending on plan) |
Pricing (output) | $20 per million audio tokens | Included in credits |
Free tier | Yes, rate-limited | 10k credits/month, no commercial rights |
Watermark | SynthID (always on) | None |
One-sentence positioning
Gemini 3.1 Flash TTS is a prompt-driven performance engine. You direct it like a voice actor. Cheapest at volume. No cloning.
ElevenLabs is a voice platform. You either pick their voices or bring your own (yours, a client's, a character's). Priciest at volume. Unmatched for cloning and English naturalness.
Now here's where each one actually falls apart — and where each one saves the day.
Voice Quality and Naturalness
Let me be real here. Both sound good. Anyone who tells you one of them is "way more natural" hasn't put them side by side in the last two weeks.
The numbers: Gemini 3.1 Flash TTS scores 1,206 Elo on the Artificial Analysis TTS Leaderboard (thousands of blind human A/B votes). ElevenLabs has held the top or near-top for most of the last two years and still leads on raw English naturalness for longer English narration.
Where each one sounds most natural — and where it slips
Gemini wins at:
Short, punchy delivery. 15-second TikTok hooks with urgency or playful tone. The 200+ audio tags ([excited], [whisper], [sigh]) produce really credible micro-expressions.
Non-English content. Japanese, Hindi, Portuguese all sounded noticeably more fluent.
Multi-speaker dialogue in a single generation. You write a back-and-forth, you get a single file with two distinct voices already mixed.
Gemini slips at:
Long-form. Official docs note output drift on longer clips; I saw it — by minute 3 the voice character shifted slightly.
Very specific emotional transitions mid-sentence if you overspecify the tags.
ElevenLabs wins at:
Long-form narration in English. Voiceovers over 2 minutes stay coherent in voice identity.
Specific branded voices. If your brand has a cloned voice, ElevenLabs is the only one of the two that supports it.
Edge cases in English pronunciation — technical jargon, brand names, abbreviations.
ElevenLabs slips at:
Granular in-line direction. You can't surgically direct mid-sentence the way Gemini's tags allow.
The honest take
For a TikTok hook under 30 seconds, I'd struggle to tell you which clip came from which tool blind. For a 3-minute YouTube narration, ElevenLabs still sounds like a real human and Gemini sounds like a really good AI. That gap is shrinking fast.
Controllability and Expression
This is where the two tools philosophically diverge.
Gemini's audio tags approach
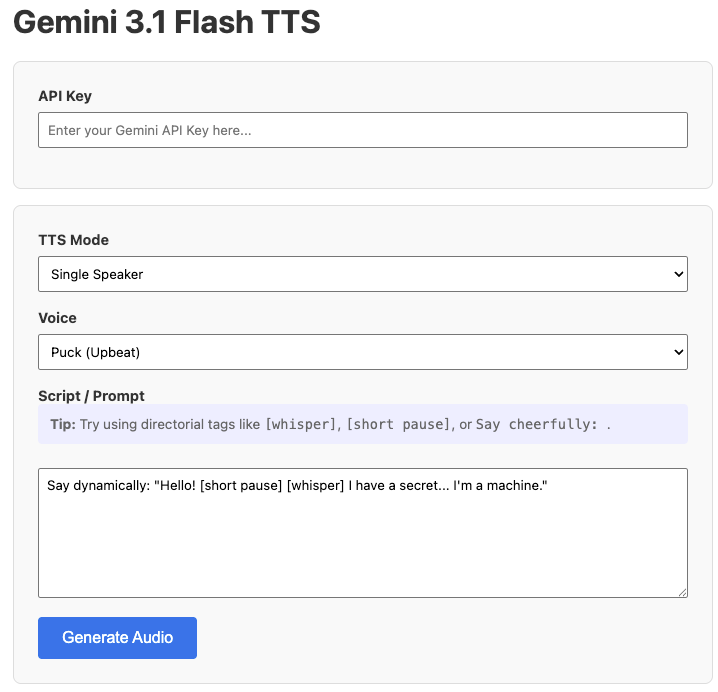
Google built Gemini 3.1 Flash TTS around 200+ audio tags — bracketed directives you drop straight into your script. Things like [warm], [impatient], [pause 2s], [whisper], [excited], [calm authority]. You also write a style prompt before the script that establishes the speaker identity and scene.
The mental model is directing an actor. You're not picking a vibe from a dropdown — you're annotating the performance at the sentence level.
Example prompt structure that worked well in my tests:
Style: A calm, confident product reviewer, early 30s, speaking to camera in a kitchen setting.Script: [warm] Okay, I tried this for a week. [pause 1s] [slight skepticism] Here's what I actually think. [enthusiastic] The battery life — [emphasis] genuinely surprised me.
When the tags are sparse and aligned with the script's meaning, this produces performances that feel like a person made specific delivery choices. When you overstuff them, it sounds like a bad audiobook. Less is more.
ElevenLabs' voice design and emotion controls
ElevenLabs' philosophy is closer to "pick the right voice, then tune it." You either select from their existing voice library, design a new voice from scratch using demographic and tonal sliders, or clone a real voice (yours, a voice actor's, a character reference).
Once you have the voice, the main controls are:
Stability — how consistent the delivery is from generation to generation. Lower = more expressive but more variable.
Similarity — how close to the reference voice the output stays.
Style exaggeration — amplifies the voice's natural quirks.
You don't get inline directives the way Gemini does. If you want a specific sentence to feel urgent, you either rewrite the text to be more urgent, or you generate a few takes and pick the best one.
Which is easier for creators without audio engineering background
Honestly? Gemini. The tags feel intuitive. ElevenLabs' sliders take time to master, but once you have a tuned voice you can run it across 100 scripts with zero tweaking.
Language and Accent Coverage
Gemini
70+ languages with native accent control. I tested Spanish (Mexican vs Castilian), Portuguese (Brazilian), and Japanese. All three produced output I'd send to a native-speaker friend for a sanity check and genuinely expect to pass.
The accent control works via natural language in the style prompt — "speak with a Newcastle English accent" or "Valley accent California English" actually changes the output. Not in a caricature way, in a real accent way. I switched one script from "Brixton" to "Newcastle" and the vowel shape noticeably changed. That's the kind of detail that used to require hiring a voice actor.
Code-mixing — switching between English and another language mid-sentence — also works better than I expected. Useful for markets like India, where creators naturally mix Hindi and English in a single line.
ElevenLabs
29+ languages on the Multilingual v2 model, with deep English, Spanish, German, French, and Portuguese. Fewer total languages than Gemini, but what they do support is extremely polished. If your content is English-first with occasional Spanish or French, ElevenLabs is still my preference.
Where ElevenLabs stretches less is in lower-resource languages. If you're creating content for Thai, Vietnamese, or Romanian audiences, Gemini's coverage is broader and the quality is closer to parity than I expected.
Bottom line on languages
1-3 major Western languages → either works, ElevenLabs has a slight polish edge.
5+ languages or lower-resource ones → Gemini.
Voice Cloning — Where They Differ Most
This is the part that can't be explained away.
What Gemini 3.1 Flash TTS does and doesn't offer
No voice cloning. Full stop.
Google's own Google Cloud documentation confirms the model works from 30 curated prebuilt voices only. You pick from names like Kore, Leda, Zephyr, Puck — each with a distinct character — and shape delivery through prompts. You cannot upload a voice sample and have the model produce audio in that voice.
This isn't a bug. It's a deliberate safety position. The model also watermarks every generation with SynthID, which is imperceptible but detectable as AI-generated. Google is playing it slow on cloning for deepfake reasons. Reasonable. But if you need cloning, this tool isn't for you.
(There is a separate Google product, Gemini 3.1 Flash Live, which is real-time conversational audio — different model, also doesn't clone.)
ElevenLabs' instant and professional voice cloning
ElevenLabs has two cloning tiers, and they're the reason a lot of creators are on this platform at all.
Instant Voice Cloning — available on Starter plan ($6/month) and above. You upload 1-5 minutes of clean audio and get back a usable voice clone in minutes. Good enough for social content, rough narration, personal use.
Professional Voice Cloning (PVC) — Creator plan ($22/month) and above. Requires 30+ minutes of high-quality audio. Output is dramatically better — this is what brands use for cloned spokesperson voices, narrator voices that need to stay stable across long-form content.
If you're a talking-head creator who wants to scale your own voice across more content than you can record — ElevenLabs. If you're a small agency running a branded voice for a client — ElevenLabs. If you're a UGC creator who wants to test 30 script variations with your own voice before actually filming — ElevenLabs.
This is not Gemini's job. Don't try to make it Gemini's job.
Real Cost for Short-Form Creators
Let me translate both pricing models into the same thing: dollars per 60-second voiceover.
Gemini 3.1 Flash TTS — token pricing
Gemini charges $1 per million text-input tokens and $20 per million audio-output tokens on the paid tier. There's also a free tier with rate limits.
For a rough reality check: a 60-second voiceover from a ~150-word script generates roughly 35,000-50,000 audio tokens plus about 200 input tokens. That works out to roughly $0.70-$1.00 per minute of output audio at the paid-tier rates.
The free tier covers a lot of experimentation before you ever see a bill. For a creator testing the tool, you'll probably never pay anything in the first few weeks. That matters.
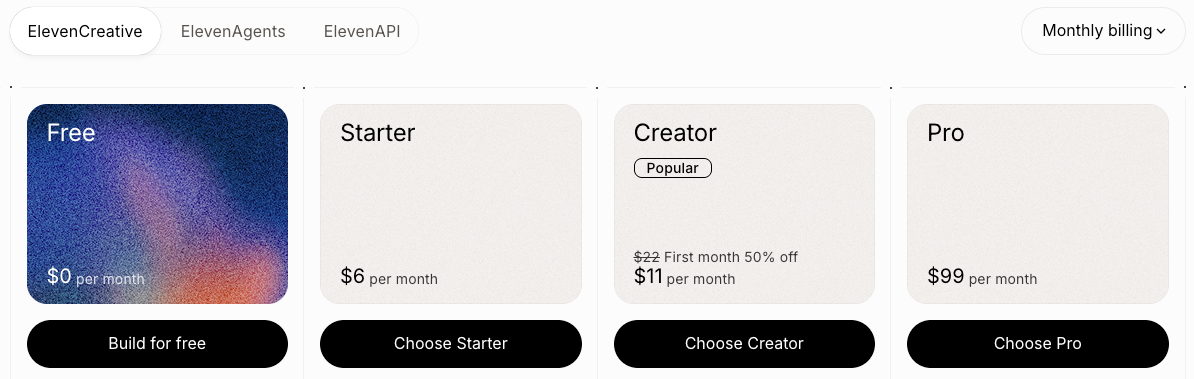
ElevenLabs — subscription tiers
ElevenLabs prices in characters, but since we think in minutes, here's the translation (assuming ~1,000 characters per minute of speech):
Plan | Monthly Cost | Audio Included | Effective $/min |
Free | $0 | ~10 min (no commercial use) | N/A |
Starter | $5 |
| $0.17/min |
Creator | $22 (or $11 first month) |
| $0.22/min |
Pro | $99 |
| $0.20/min |
Scale | $330 |
| $0.165/min |
Key thing to notice: your effective cost depends on how fully you use the plan. If you're on Creator and only generate 40 minutes a month, you're paying $0.55/min, not $0.22. The plan economics reward you for using what you pay for.
Cost per month — 50 videos at 60 seconds each
Gemini: ~$35-50/month (free tier helps).
ElevenLabs Creator: $22/month (fits comfortably and includes cloning).
For 30-100 minutes/month and cloning, ElevenLabs Creator is often cheaper. Gemini wins dramatically only at very high volume (500+ minutes) when you don't need cloning.
Best Fit by Use Case
Faceless YouTube with batch voiceovers → ElevenLabs Pro.
Short-form ads and UGC scripts → Gemini.
Multilingual content for global audiences → Gemini.
Talking-head creators using their own voice → ElevenLabs.
Conclusion — A Decision Framework
I'm going to give you the decision I'd give a peer creator texting me at 11pm trying to pick between these two. No "it depends, everyone's different" waffle.
Pick Gemini 3.1 Flash TTS if:
Most of your output is short-form (under 60 seconds)
You produce in multiple languages, especially outside the major five
You want inline emotional direction per script
You don't need voice cloning
You generate 100+ minutes of audio/month and don't need cloning
Pick ElevenLabs if:
You need voice cloning (your own, a client's, a character's)
Long-form narration is your main format
Your content is English-first and needs broadcast-grade polish
You generate 30-100 minutes/month and want predictable pricing
You want one voice to stay consistent across hundreds of pieces
Use both if your operation spans formats and languages — the combined cost is still far less than a freelance voice actor.
One thing I'm not going to pretend is that this choice stays static. Gemini 3.1 Flash TTS is three weeks old as I'm writing this. Voice cloning may land. The language gap will narrow. ElevenLabs is going to respond with something. Check back in three months. My sample size is small. Worth testing yourself before committing to an annual plan on either side.
But right now, today, for short-form video: run both through one real client script. Time it. Listen back. The answer will be obvious within an hour. That's the test that actually matters.
FAQ
Q: Which has better voice quality in 2026? For English long-form, ElevenLabs has a slight lead on naturalness. For short-form and expressive clips, Gemini 3.1 Flash TTS is at parity or better.
Q: Can I clone my own voice in Gemini 3.1 Flash TTS? No. Gemini 3.1 Flash TTS supports 30 prebuilt voices only. If voice cloning is a requirement, use ElevenLabs — the Creator plan includes professional voice cloning, and Starter includes instant cloning.
Q: Can I use both together? Yes, and a lot of creators do. ElevenLabs for your own cloned voice on talking-head content, Gemini for multilingual variants and short-form ad reads. There's no technical reason to pick just one.
Previous Posts: